들어가며 파이썬으로 운영을 위한 프로그램을 만들었습니다. 프로그램을 동작시키던 도중 예기치 못한 오류가 발생하여 재실행이 필요한 때는 언제든 발생할 수 있죠. 실제 운영 프로그램을 설계하면 API라던지 DB라던지 파이썬의 메인 프로그램과 다른 여러 환경들이 얽혀있다는 점을 잘 아실 겁니다. 이렇게 파이썬 밖에 있는 환경이 얽혀있을 때는 특히 통신 오류가 발생할 수 있는데요. 정확한 원인을 알 수 없는 오류가 발생하여 잠시 대기한 후에 재실행을 하면 다시 잘 되는 경우도 있죠. 이런 경우를 대비하기 위해 Tenacity 라이브러리를 적용하여 쉽게 코드를 재실행 할 수 있습니다. Tenacity 사용하기 Tenacity는 예외가 발생하는 경우에 다시 함수를 실행시켜서 사용자가 원하는 결과를 받고 안정적으로 ..
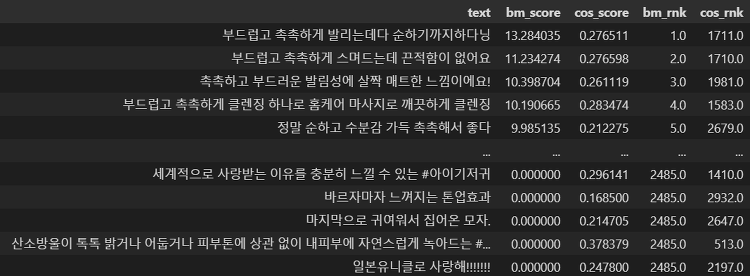
본 포스트에서는 정보 검색과 랭킹에서 사용되는 알고리즘인 RRF(Reciprocal Rank Fusion)에 대해 알아보겠습니다. 먼저 정의를 살펴본 후, 파이썬에서 구현하며 어떻게 결과가 바뀔 수 있는지 함께 확인하겠습니다. RRF(Reciprocal Rank Fusion) 알고리즘이란? RRF를 우리말로 옮기면 "상호간의 순위 융합" 정도가 되겠습니다. 말그대로, 다양한 검색 결과의 순위를 종합하여(있어보이는 표현으로는 "하이브리드하게"라는 표현이 있음) 검색 순위를 다시 매기는 하이브리드 알고리즘입니다. 다양한 검색 결과를 종합하는 이유는, 한 가지 방법론을 사용해 얻은 검색 결과만으로는 사용자들의 다양한 요구사항을 두루두루 만족시킬 수 없기 때문입니다. 여러 방법론으로 검색 결과를 얻게 되는 경우..
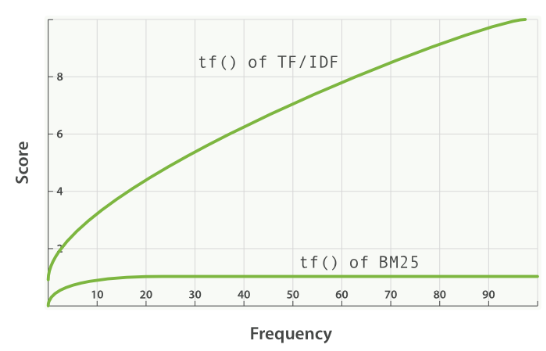
본 포스트에서는 정보 검색(Information Retrieval)에서 사용되는 BM25 알고리즘에 대해 알아보고, 파이썬에서 사용할 수 있도록 구현된 rank_bm25 라이브러리를 통해 알고리즘을 적용해보겠습니다. BM25(Best Match 25) BM25(or Okapi BM25)는 검색하고자 하는 쿼리와 다른 문서들과의 연관성을 평가하는 알고리즘입니다. 키워드 기반의 랭킹 알고리즘으로, 엘라스틱서치는 5.0부터 유사도 알고리즘으로 이 BM25를 디폴트로 적용했다고 합니다. BM25는 TF-IDF 기반으로, TF-IDF를 알고 있다면 크게 어렵지 않게 이해할 수 있습니다! TF-IDF(Term Frequency-Inverse Document Frequency) 먼저 간단하게 TF-IDF에 짚고 가겠..

들어가며 자연어 처리 모델은 입력 데이터의 형태에 굉장히 의존합니다. 동일한 의미를 가진 단어임에도 매번 형태가 달라진다면 모델의 성능을 보장할 수 없습니다. 텍스트를 최대한 규칙적이고 일관된 형태로 변환하기 위해 불필요한 정보들(불용어, 이모티콘, 특수기호, 이메일, 전화번호, 주소 등)를 제거하고, 맞춤법과 띄어쓰기 교정하기, 문장을 분리하기 등 다양한 전처리를 거치는데요,본 포스트에서는 텍스트 전처리 중 띄어쓰기와 문장 분리를 하는 방법들을 알아보겠습니다! 파이썬 ver: 3.8.10 띄어쓰기 적용하기: PyKoSpacing 띄어쓰기가 아예 되어있지 않은 한국어 문장 "아버지가방에들어가신다"는 두 가지 의미로 이해될 수 있습니다. "아버지가 방에 들어가신다"와 "아버지 가방에 들어가신다"로요. 띄어..
상황 및 문제점 구글 드라이브에 올라온 대용량 파일을 직접 다운로드 후 서버에 업로드 하려니 너무 오래 걸리고, 중간에 끊기는 문제가 발생함 해결방법 터미널에서 아래 wget 명령어를 사용하여 직접 다운로드를 받을 수 있습니다. wget --load-cookies ~/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies ~/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id={FILEID}' -O- | sed -rn 's/.*confirm=([0-9A-Za-..
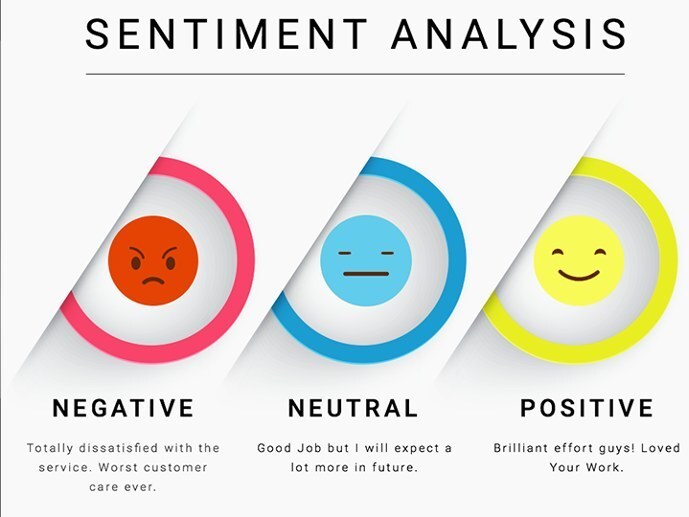
최근 새로운 자연어 처리라는 새로운 태스크를 접하게 되었습니다. 자연어 처리 과제 중에서도 텍스트에 내포된 감성에 대해 분석하는 과제인 "감성 분석(Sentiment Analysis)"과 "ABSA(Aspect-Based Sentiment Analysis)"에 대해 알아보았고, 간단하게 개념을 정리하기 위해 포스트로 남깁니다. 감성분석 ABSA에 대해 이해하기 위해서는 감성 분석에 대해 먼저 알아야겠습니다. 감성 분석이란, "텍스트에서 감정을 파악하는 자연어 처리(NLP, Natural Language Processing) 과제"입니다. 여기서 얘기하는 "텍스트"는 사람의 의견이 담긴 소비자 리뷰, 설문조사 응답, 채팅 등이 될 수 있습니다. 그 의견이 긍정적인지 부정적인지 혹은 중립적인지를 판단하는 것..
들어가며 데이터 탐색을 하다보면 다양하게 골치아픈 상황들을 마주하게 됩니다. 컬럼의 대부분이 비어있다거나, 분명 동일한 값인데 대문자 버전과 소문자 버전이 있다거나, 값의 정의가 시점에 따라 다르거나.. 등등 전처리가 필요한 경우는 신기할 정도로 많이 존재합니다. 그 중 하나가 바로 범주형 변수가 가진 카테고리가 너무 많은 경우입니다. 카테고리가 너무 많은 경우, 타겟과의 연관성을 파악하기도 번거롭고 시각화를 하더라도 한 눈에 들어오질 않습니다. 그 상태로 원핫인코딩을 진행한다면 카테고리마다 변수가 생겨 데이터가 sparse해지고, 트리 계열 모델을 학습한다면 학습 시간이 길어지면서 과적합되는 상황도 발생할 수 있을 것입니다. 위와 같은 단점을 해결하기 위해서는 해당 변수 내 카테고리 개수를 줄여야하는데..

들어가며 분석 과제를 하던 도중 범주형 변수를 숫자로 인코딩하기 위해 LabelEncoder가 필요하겠다 싶었습니다. 사용법을 확인하기 위해 사이킷런 공식문서를 살펴봤는데.. LabelEncoder는 타겟 변수 y를 하기 위해 사용하라고 써있더군요. label이 붙는 범주형 변수면 으레 사용 가능하다고 생각했었는데, 제가 오해를 하고 있었습니다. 공식문서를 다시금 잘 살펴보자는 교훈을 얻었네요. 이번 포스트는 LabelEncoder 와 OrdinalEncoder를 각각 소개하고 비교하고자 합니다. 두 인코더 모두 범주형 변수를 숫자로 인코딩하기 위해 쓰이는데요, LabelEncoder는 위에서 언급한 바와 같이 범주형 타겟 변수를, OrdinalEncoder는 범주형 입력 변수를 대상으로 합니다. 각각의..
들어가며 오랜만에 파이썬을 사용하다가 유용해보이는 기능을 발견하여 공유하고자 합니다. 바로 pandas의 style 기능입니다. 데이터 분석을 하면 데이터프레임에 찍힌 숫자나 문자와 같은 값들을 보면서 무엇이 제일 크고 작은지, 관심있게 보려는 값이 어디있는지 찾아야하는 일이 생기죠. 이때 내가 원하는 값들이 쉽게 눈에 띄지 않은 경험을 한 번쯤은 해보셨을 것 같습니다. 행, 열이 많아지면 주의 깊게 봐야하는 값이 어디에 있는지 더욱 찾기 어려워지기도 하죠. 이런 일들을 해결하기 위해 데꾸, 데이터프레임 꾸미기를 활용할 수 있습니다. 판다스의 공식 문서를 보며 유용할 것 같은 일부 함수들을 가져와 소개 드립니다. 비어있는 값, nan 강조하기 import numpy as np import pandas a..
들어가며 IT 업계에 종사하다보면 다이어그램, 시스템 설계도나 워크플로우와 같은 것들을 그릴 일들이 발생합니다. 보편적으로 피피티를 사용하는 편이긴 하지만, 최근 좋은 툴을 알게되어 소개하고자 합니다. 바로 Excalidraw 입니다. 엑스칼리드로우는 다이어그램을 손그림 느낌이 나면서도 깔끔하게 그려주는 툴입니다. 웹으로도 사용이 가능하고, Obsidian(옵시디언)과 같은 노트 애플리케이션 내에서 확장 프로그램으로서 설치하여 사용할 수도 있습니다. 다만 웹으로는 한 개의 캔퍼스만 사용할 수 있고, 한글 폰트가 예쁘게 나오지 않아서 본 포스트에서는 옵시디안을 이용해 사용하는 방법을 소개하겠습니다! 옵시디언 설치 옵시디언 다운로드 홈페이지에서 환경에 맞는 설치 파일을 다운로드 합니다. 이후 첫 화면에서 언..