
들어가며 저는 책을 읽고나면 인상적이어서 기억하고 싶은 부분을 남겨놓곤 합니다. 그런 부분들은 단편적으로 기록하기도 하지만, 잘 모으고 연결해서 하나의 글로 완성하고 싶은 바람도 있습니다. 평론가들이 시나 소설을 읽고 남긴 평론들을 보면 어떤 주제와 의견을 갖고 그 작품의 내용을 잘 편집해놨더라고요. 평론급으로 독후감을 쓰겠다는 건 아니지만.. 그래도 내가 인상적이었던 부분들과 말하고 싶은 내용을 자연스럽게 연결하는 글의 초안을 작성하거나 제안해주면 좋겠다는 마음으로 독후감 챗봇 만들기를 해보았습니다. HuggingChat Assistants 소개 챗봇 만들기를 위해 사용한 플랫폼은 허깅페이스의 HuggingChat입니다. 여기서는 Assistants라고 하여 사용자가 직접 챗봇을 만들 수 있는 서비..

들어가며 최근 RAG PoC를 수행하며.. 질문에 대해 직접 평가도 수행해보고 있습니다. 자동화를 시키지 않고 직접 질문을 이해하고, 검색 결과와 생성 결과를 확인하며 평가했는데요. 평가를 하며 얻은 생각들을 정리해보고자 포스트를 작성하였습니다. 자동화를 하지 않은 이유는 사람이 직접 확인하고 단계마다 평가해야, 어떤 지점에서 오류가 발생하는지 구체적으로 확인하고 분석할 수 있기 때문이었습니다. 평가를 자동화한다면 어떻게 해야하는지.. 모호한 부분도 있었구요. g-eval을 쓰라고들 하지만,, 분석가라면 응당 직접 평가도 수행해야 개선점을 찾을 수 있지 않을까?? 하여 평가도 나름 진심으로 임했네요. (물론 문제 수가 너무 많다면 LLM에게 시켜야겠지만요ㅠㅠ) 평가 항목과 내용 수작업으로 하는 성능 평가..

들어가며 비교적 최근에 생긴 빅데이터 분석기사라고 하는 기사 자격증이 있습니다. 데이터 관련 경력을 쌓고 있는 저를 스스로 시험할 수 있게 하는 좋은 자격증인 것 같더라고요. 심지어 생긴지 오래되지 않아서 난이도도 그렇게 높지 않다고 해요. 그래서 올해 4월 초에 빅데이터 분석기사 필기 시험을 치루었습니다. 공부는 충분하게 하지 못했지만 그동안 다져온 경력으로 믿음을 갖고(?) 대응했고 다행히 한번에 합격했습니다.. 원하는 고사장에서 시험을 보고 싶다면 접수를 빨리 하시는 것이 좋겠습니다. 저는 실기 접수가 열리고 나서 3~4일 후 쯤에 접수를 하려고 데이터자격검정 사이트에 들어갔는데, 서울에서 한 2개 고사장 정도만 자리가 남아있더라고요. 집에서 1시간 거리에 있는 한 대학교에서 시험을 치루었습니다. ..

들어가며 최근 제안서를 작성하는 업무를 수행했습니다. 제안서를 작성하며 정말 많은 고생을 했다는 경험은 여러 차례 들어보았는데, 드디어 저한테도 순서가 온 것이지요.. 여러 난관이 있었지만, 생전 처음 제안서를 마주하며 특히 크게 와닿은 세 가지는 새롭게 주어진 일을 받아들일 자세, 남을 설득하는 자세, 큰 그림을 그리는 자세였습니다. 본 포스트는 이 세 가지를 중심으로 제가 느꼈던 점들을 공유하고자 작성하였습니다. 개인적인 회고를 위해 작성한 글이며, 제안서 작성 방법론은 없습니다. 스리슬쩍 사라질 수도 있습니다. 새로운 일을 받아들일 결심: (이걸요? 제가요? 왜요?) 네 앞에서 언급했다시피 이번 기회를 통해 처음으로 제안서를 접하였습니다. 그나마 다행이었던 점은 제안서 전체를 작성하는 것이 아니라..

들어가며 IT 산업 종사자로서 생성형 AI 가 대두되기 시작하며 과연 데이터 사이언티스트/분석가란 직무는 어떻게 될까? 어떤 영향을 받을까? 업무에서 생산성이 올랐을 거라 기대되니 채용을 줄이려나? 계속 이 일을 할 수 있을까..?🥲 하는 꼬리에 꼬리를 무는 질문들을 하게 되었습니다. 마침 데이터리안에서 이런 고민들을 해소해줄 수 있는 세미나가 있다고 하여 바로 신청해봤습니다. (#내돈내산) 3월에도 데이터리안에서 진행하는 퍼널 분석 세미나를 들었는데, 사용자를 이해하면서 서비스를 개선시키는 분석은 이런 것이구나 하는 걸 알 수 있어서 흥미롭게 봤었습니다. 퍼널 분석이라는 방법론도 흥미로웠지만 실무 경험들을 바탕으로 한 질의응답도 알찼던 것으로 기억합니다. 그 경험을 바탕으로 데이터리안에서 진행하는 세..

들어가며머신러닝, AI 프로젝트에서는 모델 학습을 위해서 학습 데이터를 구축합니다. 이미 잘 마련된 데이터를 바로 가져다 쓰면 너무나도 편리하겠지만, 그런 해피한 상황은 잘 없는 것 같습니다. 텍스트나 이미지처럼 비정형 데이터는 특히 더 그런 것 같구요. "Garbage in, garbage out" 머신러닝 필드에서 유명한 격언이죠. 학습 데이터의 품질이 보장되어야 모델의 성능과 신뢰도를 보장할 수 있습니다. 학습 데이터를 잘 만들려면 적절한 가이드라인이 필요합니다. 보통 모델 학습을 위해 몇 만건 씩은 데이터가 필요한데, 한 명이서 그 많은 작업을 할 수 없으니 여러 명이서 작업을 하게 되고요. 여러 명이서 작업하는데 각자의 기준을 갖고 데이터를 만들면.. 데이터 품질이 보장되었다고 하기 어렵습니다..
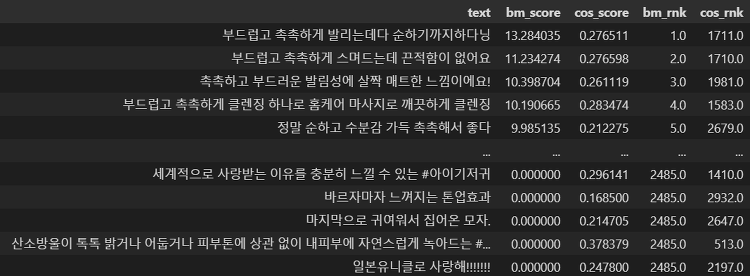
본 포스트에서는 정보 검색과 랭킹에서 사용되는 알고리즘인 RRF(Reciprocal Rank Fusion)에 대해 알아보겠습니다. 먼저 정의를 살펴본 후, 파이썬에서 구현하며 어떻게 결과가 바뀔 수 있는지 함께 확인하겠습니다. RRF(Reciprocal Rank Fusion) 알고리즘이란? RRF를 우리말로 옮기면 "상호간의 순위 융합" 정도가 되겠습니다. 말그대로, 다양한 검색 결과의 순위를 종합하여(있어보이는 표현으로는 "하이브리드하게"라는 표현이 있음) 검색 순위를 다시 매기는 하이브리드 알고리즘입니다. 다양한 검색 결과를 종합하는 이유는, 한 가지 방법론을 사용해 얻은 검색 결과만으로는 사용자들의 다양한 요구사항을 두루두루 만족시킬 수 없기 때문입니다. 여러 방법론으로 검색 결과를 얻게 되는 경우..
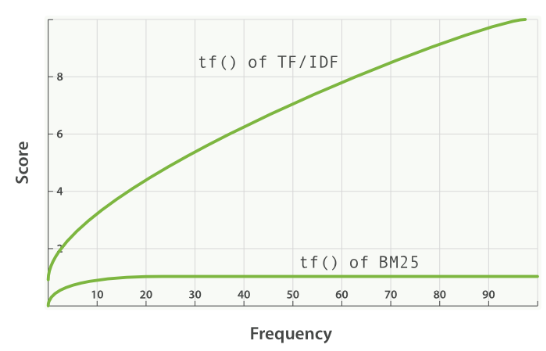
본 포스트에서는 정보 검색(Information Retrieval)에서 사용되는 BM25 알고리즘에 대해 알아보고, 파이썬에서 사용할 수 있도록 구현된 rank_bm25 라이브러리를 통해 알고리즘을 적용해보겠습니다. BM25(Best Match 25) BM25(or Okapi BM25)는 검색하고자 하는 쿼리와 다른 문서들과의 연관성을 평가하는 알고리즘입니다. 키워드 기반의 랭킹 알고리즘으로, 엘라스틱서치는 5.0부터 유사도 알고리즘으로 이 BM25를 디폴트로 적용했다고 합니다. BM25는 TF-IDF 기반으로, TF-IDF를 알고 있다면 크게 어렵지 않게 이해할 수 있습니다! TF-IDF(Term Frequency-Inverse Document Frequency) 먼저 간단하게 TF-IDF에 짚고 가겠..
들어가며 IT 업계에 종사하다보면 다이어그램, 시스템 설계도나 워크플로우와 같은 것들을 그릴 일들이 발생합니다. 보편적으로 피피티를 사용하는 편이긴 하지만, 최근 좋은 툴을 알게되어 소개하고자 합니다. 바로 Excalidraw 입니다. 엑스칼리드로우는 다이어그램을 손그림 느낌이 나면서도 깔끔하게 그려주는 툴입니다. 웹으로도 사용이 가능하고, Obsidian(옵시디언)과 같은 노트 애플리케이션 내에서 확장 프로그램으로서 설치하여 사용할 수도 있습니다. 다만 웹으로는 한 개의 캔퍼스만 사용할 수 있고, 한글 폰트가 예쁘게 나오지 않아서 본 포스트에서는 옵시디안을 이용해 사용하는 방법을 소개하겠습니다! 옵시디언 설치 옵시디언 다운로드 홈페이지에서 환경에 맞는 설치 파일을 다운로드 합니다. 이후 첫 화면에서 언..
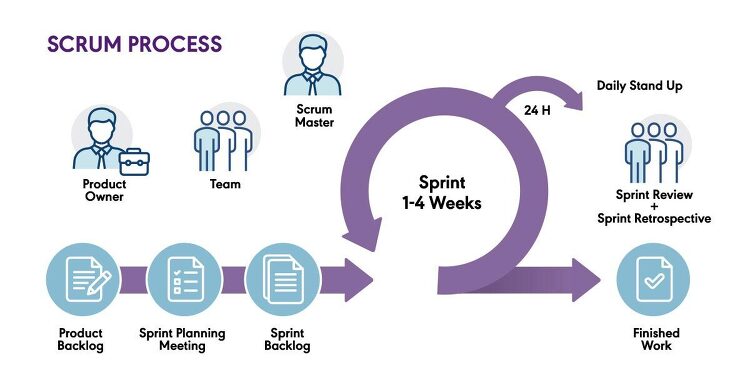
저는 IT 산업에 종사하고는 있지만 소프트웨어가 어떤 과정을 거쳐 만들어지는지는 잘 모르고 있었습니다. 주로 데이터 분석, 머신러닝 개발 일을 하기 때문에 제품/서비스를 만드는 과정에 전부 관여하기 보다는 데이터로 무언가를 하는 단계에만 관여를 했죠. 물론 그 "데이터로 무언가를 하는 단계" 에서 내부적으로 어떤 과정을 거쳐야 하는지는 잘 알고 있었습니다. 해결해야하는 과제를 정의하고, 데이터를 수집하고, 분석하고, 모델을 학습하고, 테스트하고 배포하는 절차야 늘 해왔기 때문이죠. 혹시나 나중에 직접 제품이나 서비스를 기획하거나 대규모 프로젝트에 참여해야할 수도 있으니, 데이터를 이용하는 단계 이상으로, 제품/서비스 릴리즈를 위해 어떤 정석적인 과정을 거치는지 학습할 필요가 있다고 생각했습니다. 주변의 ..