본 포스트에서는 정보 검색(Information Retrieval)에서 사용되는 BM25 알고리즘에 대해 알아보고, 파이썬에서 사용할 수 있도록 구현된 rank_bm25 라이브러리를 통해 알고리즘을 적용해보겠습니다.
BM25(Best Match 25)
BM25(or Okapi BM25)는 검색하고자 하는 쿼리와 다른 문서들과의 연관성을 평가하는 알고리즘입니다. 키워드 기반의 랭킹 알고리즘으로, 엘라스틱서치는 5.0부터 유사도 알고리즘으로 이 BM25를 디폴트로 적용했다고 합니다. BM25는 TF-IDF 기반으로, TF-IDF를 알고 있다면 크게 어렵지 않게 이해할 수 있습니다!
TF-IDF(Term Frequency-Inverse Document Frequency)
먼저 간단하게 TF-IDF에 짚고 가겠습니다. TF-IDF는 단어의 빈도(Term Frequency)와 역 문서 빈도(Inverse Document Frequency)를 이용해 단어마다 중요도를 계산하는 방법입니다. TF는 각 문서 내에서 단어의 빈도, DF는 문서 집합 내에서 각 단어가 등장한 문장의 수로, IDF는 이 DF에 반비례하는 값입니다. 단어의 TF-IDF가 높다는 것은 특정 문서에서 그 단어가 많이 사용되고 있고, 다른 문서들에서는 그 단어가 잘 나타나지 않는다는 의미입니다.
BM25 수식 이해
쿼리 Q가 주어졌을 때 문서 D에 대한 BM25 점수는 아래 수식을 통해 계산됩니다. 쿼리 Q는 키워드 q1, q2, ..., qn을 포함합니다.

먼저 IDF(q_i)는, 쿼리의 키워드 q_i에 대한 IDF(Inverse Document Frequency)입니다. 위에 TF-IDF 정의에서 살펴봤던 IDF와 크게 다르지 않습니다. 해당 키워드가 전체 문서 집단에서 자주 등장한다면 가중치를 적게 주고, 자주 등장하지 않는다면 큰 가중치를 준다는 의미입니다.
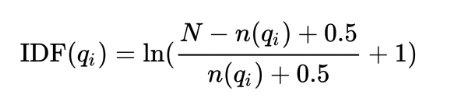
- N: 총 문서의 개수
- n(q_i): 해당 키워드를 포함하는 문서의 개수
그리고 f(q_i, D)는 문서 D에서 키워드 q_i가 얼마나 자주 나타나는가를 의미합니다. 문서에 해당 키워드가 자주 나타나면 점수가 높아지는 것이죠.
|D| / avgdl은 문서의 길이에 대한 항인데요, 해당 문서 D가 평균적인 문서 길이에 비해 얼마나 긴 문서인지를 고려합니다. 평균 대비 문서의 길이가 길다면 점수를 낮추는 역할을 하는 건데요, 매우 긴 문서에서 키워드가 한 번 등장하는 것과 매우 짧은 댓글 같은 문서에서 한 번 등장하는 것 중 후자가 더 중요도가 높다고 의미 부여를 하는 것이죠.
k1과 b는 알고리즘의 파라미터인데요, k1은 키워드의 빈도를 통해 점수에 주는 영향을 제한합니다. 키워드의 TF가 k1보다 작다면 점수가 빠르게 증가하지만, k1보다 커지는 경우 패널티를 받아 키워드가 많이 등장해도 스코어에 주는 영향이 크지 않다고 합니다.
b는 문서의 길이에 대한 중요도를 제한하는 역할을 합니다. b가 커지면 평균 대비 문서의 길이에 대한 항의 중요도가 커져 문서가 길수록 패널티를 줄 수 있게 됩니다. 반대로 b가 작을수록 문서의 길이를 무시할 수 있게 되는 것이고요. 일반적으로 b는 0.75를 사용한다고 합니다.
두 개 파라미터를 통해 TF항이 정규화됨으로써, 아래 그래프에서 확인할 수 있듯이 BM25의 Term Frequency는 TF-IDF와 다르게 특정 값 이상을 갖기 어려워졌습니다. 값이 안정적이라는 의미겠죠.

rank_bm25 라이브러리
python: v3.8.10
rank_bm25: v0.2.2
BM25 알고리즘 사용을 위해 rank_bm25 라이브러리를 설치합니다. BM25뿐만 아니라 그 변형인 BM25L, BM25+ 도 제공하고 있다고 합니다.
pip install rank_bm25
저는 모두의 말뭉치에서 ABSA 과제를 위해 제공하는 데이터를 적용해보았습니다. 아래 예시에서는 편의상 띄어쓰기 기준으로 텍스트를 구분하였으나, 의미론상 구분을 위해 다른 한국어 토크나이저를 적용할 수도 있습니다. 그리고 그 편이 성능에 더 좋은 영향을 줄 것이라는 건 자명하겠죠..!
import jsonlines
import pandas as pd
from rank_bm25 import BM25Okapi
def read_jsonl(path):
data = list()
with jsonlines.open(path) as f:
for line in f:
data.append(line)
return data
train_data = read_jsonl('./data/nikluge-sa-2022-train.jsonl')
corpus = [data['sentence_form'] for data in train_data]
tokenized_corpus = [doc.split(" ") for doc in corpus] # 띄어쓰기 기준 구분
for idx, doc in enumerate(tokenized_corpus): # 데이터 예시
if idx < 5:
print(doc)['둘쨋날은', '미친듯이', '밟아봤더니', '기어가', '헛돌면서', '틱틱', '소리가', '나서', '경악.']
['이거', '뭐', '삐꾸를', '준', '거', '아냐', '불안하고,', '거금', '투자한', '게', '왜', '이래..', '싶어서', '정이', '확', '떨어졌는데', '산', '곳', '가져가서', '확인하니', '기어', '텐션', '문제라고', '고장', '아니래.']
['간사하게도', '그', '이후에는', '라이딩이', '아주', '즐거워져서', '만족스럽게', '탔다.']
['샥이', '없는', '모델이라', '일반', '도로에서', '타면', '노면의', '진동', '때문에', '손목이', '덜덜덜', '떨리고', '이가', '부딪칠', '지경인데', '이마저도', '며칠', '타면서', '익숙해지니', '신경쓰이지', '않게', '됐다.']
['안장도', '딱딱해서', '엉덩이가', '아팠는데', '무시하고', '타고', '있다.']
해당 데이터는 다양한 상품들의 리뷰 데이터인데요, 이 리뷰 데이터들 중 "촉촉하고 부드럽다'라고 하는 쿼리와 연관성이 높은 리뷰들이 어떤 것들이 있는지 BM25 알고리즘을 이용하여 검색해보겠습니다. 아래와 같이 토큰화된 코퍼스를 등록하고, get_scores 메소드를 이용해 문서마다 점수를 얻을 수 있습니다. 쿼리에 등장한 "촉촉"이라고 하는 단어를 동일하게 포함하고 있는 문서들이 점수가 높은 것을 확인할 수 있었습니다. 길이가 짧은 "촉촉하고 지속력도 있어요"라고 하는 리뷰가 점수가 가장 높았구요. 반대로 전혀 관련 없는 내용들이 등장하는 문서들은 점수가 0점으로 나오고 있네요.
bm25 = BM25Okapi(tokenized_corpus)
query = "촉촉하고 부드럽다"
tokenized_query = query.split(" ")
doc_scores = bm25.get_scores(tokenized_query)
result = pd.DataFrame({
'text': corpus,
'score': doc_scores
})
result.sort_values(['score'], ascending=False)
get_top_n 메소드를 사용하면 점수가 높은 상위 N개 문서들을 따로 확인할 수 있습니다. 점수가 높은 상위 일부 문서만 확인하고 싶을 때 유용하게 사용할 것 같습니다.
for doc in bm25.get_top_n(tokenized_query, corpus, n=5):
print(doc)촉촉하고 지속력도 있어요
촉촉하고 가벼운 밀착력에 완벽한 커버력
일단 촉촉하고 밀착력도 좋은편! ㅎㅎ
끈적임없이 촉촉하고 산뜻해서 너무 조아~ :)
촉촉하고 부드러운 발림성에 살짝 매트한 느낌이에요!
정리하자면, BM25는 해당 키워드를 문서에서 많이 포함하고 있을 때, 문서의 길이가 너무 길지 않을 때, 다른 문서에서 잘 등장하지 않는 단어를 포함할 때 높은 점수를 준다는 것을 알 수 있었습니다. 파이썬 라이브러리 rank_bm25를 이용해 쉽게 알고리즘을 적용할 수 있으니, 키워드 기반으로 유사한 문장, 구문을 검색하고자 한다면 한번 실험해보시길 바랍니다!
참고
https://littlefoxdiary.tistory.com/12
[Python] IR 검색 알고리즘 - BM25 / 엘라스틱서치 랭킹 알고리즘 / 파이썬 rank_bm25 모듈로 문서 검색
키워드 기반의 랭킹 알고리즘 - BM25 BM25(a.k.a Okapi BM25)는 주어진 쿼리에 대해 문서와의 연관성을 평가하는 랭킹 함수로 사용되는 알고리즘으로, TF-IDF 계열의 검색 알고리즘 중 SOTA 인 것으로 알려
littlefoxdiary.tistory.com
https://github.com/dorianbrown/rank_bm25
GitHub - dorianbrown/rank_bm25: A Collection of BM25 Algorithms in Python
A Collection of BM25 Algorithms in Python. Contribute to dorianbrown/rank_bm25 development by creating an account on GitHub.
github.com
https://www.elastic.co/kr/blog/practical-bm25-part-2-the-bm25-algorithm-and-its-variables
실용적인 BM25 - 제2부: BM25 알고리즘과 변수
BM25는 Elasticsearch의 기본 유사성 순위(정확도) 알고리즘입니다. 등식을 심층적으로 살펴보고 변수 뒤에 숨겨진 개념을 탐색하여 그 작동 방식에 대해 자세히 알아보세요.
www.elastic.co
'繩鋸木斷水滴石穿 > 기타' 카테고리의 다른 글
| [데이터] 어노테이션 가이드 작성하는 방법 (0) | 2024.04.30 |
|---|---|
| [IR] RRF(Reciprocal Rank Fusion) 설명과 파이썬 코드 (2) | 2023.12.30 |
| [Tool] Excalidraw 사용법: 깔끔하고 멋진 다이어그램 툴 추천 (4) | 2023.07.16 |
| [후기] 유데미 소프트웨어 엔지니어링 강의 후기: Software Engineering 101: Plan and Execute Better Software (1) | 2023.05.12 |
| [비즈니스] 벤치마크데이: 효율적인 벤치마킹을 수행하는 방법 (0) | 2023.02.10 |