들어가며
데이터 탐색을 하다보면 다양하게 골치아픈 상황들을 마주하게 됩니다. 컬럼의 대부분이 비어있다거나, 분명 동일한 값인데 대문자 버전과 소문자 버전이 있다거나, 값의 정의가 시점에 따라 다르거나.. 등등 전처리가 필요한 경우는 신기할 정도로 많이 존재합니다.
그 중 하나가 바로 범주형 변수가 가진 카테고리가 너무 많은 경우입니다. 카테고리가 너무 많은 경우, 타겟과의 연관성을 파악하기도 번거롭고 시각화를 하더라도 한 눈에 들어오질 않습니다. 그 상태로 원핫인코딩을 진행한다면 카테고리마다 변수가 생겨 데이터가 sparse해지고, 트리 계열 모델을 학습한다면 학습 시간이 길어지면서 과적합되는 상황도 발생할 수 있을 것입니다.
위와 같은 단점을 해결하기 위해서는 해당 변수 내 카테고리 개수를 줄여야하는데요, 이 포스트에서는 그 아이디어들에 대해 알아보겠습니다.
[Idea 1] 빈도가 적은 클래스는 합치기
일반적으로 카테고리마다 데이터 빈도를 집계해보면 고르게 나타나지는 않습니다. 보통은 소수의 카테고리에 데이터가 집중하여 분포되는 경우가 많더라구요. 데이터 건수가 적은 카테고리들은 이후에도 나타날 가능성이 적다고 여겨지기 때문에 그들끼리 합치는 방안이 합리적일 수 있겠습니다. 단, 실제로 합치는 것이 유의미할 것인지는 분석가들끼리 협의가 되어야할 것입니다.
카테고리를 합치는 작업을 직접 값을 대치함으로써 진행할 수도 있지만, 너무 많다면 인코더의 파라미터를 이용할 수도 있습니다. sklearn의 OrdinalEncoder에서는 min_frequency 또는 max_categories 파라미터를 사용하여 구현할 수 있습니다.
👉 min_frequency: (양의 정수인 경우) 지정한 값보다 데이터 건수를 적게 갖고 있는 카테고리들은 하나로 통합, (0보다 크고 1보다 작은 float인 경우) 지정한 비율보다 데이터의 비율이 적은 카테고리들을 하나로 통합
👉max_categories: 카테고리별 데이터 건수의 순위를 사용하여 최대 카테고리 개수를 제한함
아래는 min_frequency를 6으로 지정하여 데이터 건수가 6보다 작은 카테고리들(dog, snake)은 모두 하나의 카테고리로 통합하는 예시입니다.
import numpy as np
from sklearn.preprocessing import OrdinalEncoder
X = np.array([['dog'] * 5 + ['cat'] * 20 + ['rabbit'] * 10 + ['snake'] * 3], dtype=object).T
enc1 = OrdinalEncoder(min_frequency=6).fit(X)
print(enc1.infrequent_categories_)
print(enc1.transform(np.array([['dog'], ['cat'], ['rabbit'], ['snake']])))
[Idea 2] (가능하다면) 변수를 분할하기
동등한 조합들로 이루어진 경우
여기 MBTI라고 하는 변수가 있습니다. 요즘 많이들 아시다시피 MBTI는 4개의 유형(에너지 방향, 인식 방식, 판단, 생활 양식)마다 2종류의 값을 갖고 있습니다. 이 조합별로 총 16개 타입의 MBTI 유형을 구성할 수 있는데요. 만약 MBTI를 하나의 변수로 나타내면 16개 카테고리를 갖게 되겠죠.
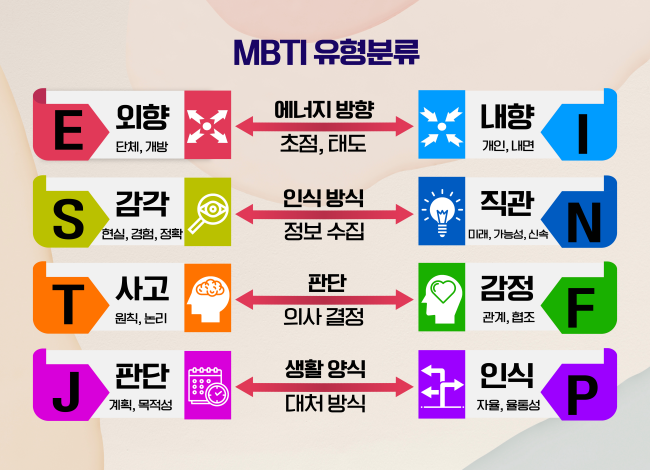
하지만 MBTI라는 변수를 이해하고 나면 이 하나의 변수를 4개 변수로 분할할 수 있다고 바로 판단할 수 있을 것입니다.
⭐ MBTI → (1) 에너지 방향 변수 (2) 인식 변수 (3) 판단 변수 (4) 생활 변수
기존에 하나의 변수였던 것을 4개로 쪼갤 수 있고, 각 변수들은 오직 2개의 값만을 갖고 있습니다. 변수가 늘어나긴 했지만 변수마다 카테고리는 줄어들어 직관적으로 이해하기 쉽게 변형되었습니다.
계층적인 관계로 이루어진 경우
계층적인 관계로 이루어진 변수도 마찬가지로 변수를 잘 이해함으로써 분할할 수 있습니다. 예를 들어 도로명주소라고 하는 변수가 있습니다. 이 변수는 동/층/호를 제외하고 건물 개수만큼 카테고리를 갖고 있다고 합시다. 예를 들어, 서울역의 경우 주소가 "서울특별시 용산구 한강대로 405" 입니다. 가장 먼저 광역시/도, 이후 시/군/구 그리고 도로명, 건물번호로 표기하는 체계를 갖고 있습니다. 보시다시피 하위 체계의 값들은 상위 체계 값에 종속적이죠. 용산구는 서울특별시에 속한다는 뜻입니다.
주소 변수의 체계를 이해했으니 이제 분할할 수 있습니다.
⭐ 주소 → (1) 광역시/도 (2) 시/군/구 (3) 도로명 (4) 건물번호
다만 이런 분할을 거치고 나면 파생된 변수 내에서 중복값이 발생할 수 있습니다. 분명히 다른 도로에 있는 두 개 건물인데, 도로명만 다르고 건물번호가 405로 동일하게 있는 상황말이죠. 이런 단점이 있긴 하지만, 아무튼 엄청나게 많았던 주소 변수의 카테고리들을 변수를 분할함으로써 줄일 수 있었다는 점을 알고 갑시다.
[Idea 3] WoE 사용하기
위의 방법들은 모델의 타겟을 고려하지 않고 변수 자체만을 사용하였는데요, 타겟을 활용하여 카테고리를 줄이는 아이디어도 있습니다. 바로 WoE(Weight of Evidence)입니다. 본래 woe는 binary 변수를 타겟으로 하는 로지스틱 회귀분석에서 범주형 변수와 타겟의 연관성을 살펴보면서, 해당 변수가 타겟을 예측하는 데 있어 유의미한지를 확인하기 위해 사용되었습니다. 특히 전통적인 신용평가 모형에서 많이 활용되었습니다.
WoE와 IV의 개념
WoE(Weight of Evidence)
WoE는 Bads(불량 고객) 대비 Goods(우량 고객)의 비율에 대한 로그값으로 정의합니다. WoE가 양수라면 우량 고객이 많다는 것이고, 음수라면 불량 고객이 많다는 것으로 해석할 수 있겠죠. 여기서 불량 고객은 대출을 갚지 않은 고객, 우량 고객은 대출금을 상환한 고객을 의미합니다. 신용평가 외에 다른 과제인 경우 이벤트 발생, 미발생으로 정의할 수도 있습니다.

WoE 계산 절차는 단순합니다.
1️⃣ 카테고리마다의 Goods/Bads 건수를 집계합니다.
2️⃣ 카테고리마다 Goods/Bads의 비율을 계산합니다. 이때 분모는 전체 Goods/Bads 건수입니다.
3️⃣ 2의 결과를 사용하여 카테고리마다 WoE를 계산합니다.
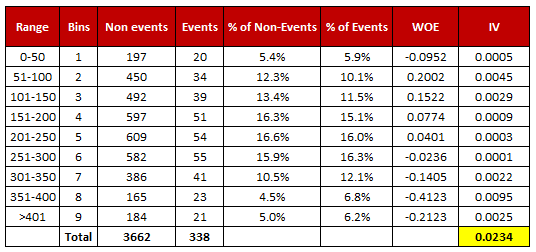
WoE가 유사하다는 것은 각 카테고리와 타겟과의 연관성이 유사하다는 의미이니, 하나의 카테고리로 취급하는 것이 아이디어입니다. 위 표에서는 Range 151-200과 Range 201-250의 WoE가 0.07, 0.04로 유사하니(유사하다는 기준이 특별히 존재하는 건 아니지만 단순 예시이므로 넘어가겠습니다), 즉 두 개 카테고리에서 이벤트 발생 비율과 미발생비율이 유사하니 합쳐서 사용해도 되지 않을까? 하는 것이죠.
(참고) IV(Information Value)
해당 범주형 변수가 타겟에 유의미한지를 판단하는 지표로, 아래와 같이 계산합니다.

IV값에 따라 해당 변수가 예측력이 있는지에 대한 판단은 아래 기준표를 참고하세요.

마치며
이상으로 카테고리를 많이 보유하고 있는 범주형 변수를 분석하기 위해 카테고리 개수를 줄이는 여러가지 아이디어들에 대해 다루어 보았습니다. 직관적인 시각화 결과와 인사이트를 얻기 위해, 모델 학습시 과적합을 방지하기 위해 카테고리 개수를 줄이는 전처리를 고려해보시길 바랍니다. 도움이 되었으면 좋겠고 궁금한 점이 있다면 댓글로 알려주세요, 감사합니다~👏
참고
https://scikit-learn.org/stable/modules/preprocessing.html#encoder-infrequent-categories
6.3. Preprocessing data
The sklearn.preprocessing package provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream esti...
scikit-learn.org
https://www.listendata.com/2015/03/weight-of-evidence-woe-and-information.html
Weight of Evidence (WOE) and Information Value (IV) Explained
Learn how to calculate Weight of Evidence and Information Value to improve your predictive model along with SAS, R and Python code
www.listendata.com
Logistic 예측 모형에서의 변수 선택 방법 - Information Value
이건 좀 다른 이야기일 수 있는데, 로지스틱 회귀예측 모형을 만들 때, 변수를 선택하는 방법론이 있어서 짚고 넘어가 보려고 합니다. 이 선택방법은 회귀분석 결과를 설명 가능하게 하는 것이
recipesds.tistory.com
'繩鋸木斷水滴石穿 > AI | 머신러닝' 카테고리의 다른 글
| [NLP] 텍스트 전처리: 파이썬에서 띄어쓰기, 문장 분리 라이브러리 사용하기 (3) | 2023.11.26 |
|---|---|
| [NLP] 감성 분석과 ABSA(Aspect-Based Sentiment Analysis) 개념 (1) | 2023.10.09 |
| [sklearn] LabelEncoder와 OrdinalEncoder 비교 (0) | 2023.08.27 |
| [모니터링] 2) 드리프트 감지 방법: KS 검정과 PSI (2) | 2023.05.28 |
| [모니터링] 1) model drift의 개념과 원인(data drift, label drift, concept drift) (0) | 2023.04.16 |