
들어가며 RAG 시스템을 사용하며 그 구조에 대해 알고는 있었습니다. 심지어 이 시스템의 성능을 높이려면 어떤 요소를 추가하며 고도화해야하는지도 구상했습니다. 다만 제가 직접 밑단에서부터 구축해본 경험은 없더라구요. 만들어진 시스템을 통해 데이터를 구축하고, API를 사용해 검색과 생성 결과를 얻어본 적은 있지만 파이썬을 사용해 좀 더 기본적인 바탕을 익혀보고자 강의를 수강하였습니다. https://www.inflearn.com/course/%EC%9E%85%EB%AC%B8%EC%9E%90%EB%A5%BC%EC%9C%84%ED%95%9C-%EB%9E%AD%EC%B2%B4%EC%9D%B8-%EA%B8%B0%EC%B4%88/dashboard [지금 무료]입문자를 위한 LangChain 기초 강의 | 판다스 ..

한빛미디어 ‘나는리뷰어다2024’ 서평단으로서 선정한 세 번째 도서는 ‘데이터 드리브 리포트’입니다. 이번에는 실물 책이 아닌 e-book으로 책을 받아봤는데요. 무겁지도 않고 어디서든 볼 수 있었지만.. 역시 독서는 실물 책으로 하는 것이 집중도 잘 되고 더 읽는 기분이 나서 좋은 것 같네요..😅도서 선정 이유 데이터 직무를 계속 하고 싶은 사람으로서 분석 결과를 갖고 팀원들, 다른 부서, 나아가 고객과도 잘 소통하기 위해서 이번 도서를 선정했습니다. 고백하자면 그동안 업무를 하면서 분석을 잘했을지언정 누구나 잘 이해하게 내용을 전달했나? 에 대한 대답은 잘 모르겠습니다. 스토리텔링이 중요하다는데 그런건 소설 쓰는 사람들이 알아야 하는 것 아니었나 의문을 가진 채로 어디서부터 시작해야 하나 막막해하며..

한빛미디어 '나는리뷰어다2024' 서평단으로서 선정한 두 번째 도서는 '실무로 통하는 인과추론 with 파이썬' 입니다. https://www.hanbit.co.kr/store/books/look.php?p_code=B6208936856 실무로 통하는 인과추론 with 파이썬 데이터 기반의 통찰력 있는 의사결정을 위한 인과추론, 효율적인 영향력 분석을 통한 성공적인 비즈니스 정책 결정 www.hanbit.co.kr 도서 선정 이유 머신러닝 모델을 학습하기 위해 많은 변수를 수집할 때마다 생각합니다. 이거 진짜 결과에 영향 주는 변수 맞아..? 일단 활용 가능한 것들 다 넣어보는 거 아녀..? 사실 하나하나의 변수가 결과와 직접적인 관련이 없어 보이더라도 다른 변수들과의 상호 작용으로 인해 결과와 연관이 ..
들어가며 데이터 탐색을 하다보면 다양하게 골치아픈 상황들을 마주하게 됩니다. 컬럼의 대부분이 비어있다거나, 분명 동일한 값인데 대문자 버전과 소문자 버전이 있다거나, 값의 정의가 시점에 따라 다르거나.. 등등 전처리가 필요한 경우는 신기할 정도로 많이 존재합니다. 그 중 하나가 바로 범주형 변수가 가진 카테고리가 너무 많은 경우입니다. 카테고리가 너무 많은 경우, 타겟과의 연관성을 파악하기도 번거롭고 시각화를 하더라도 한 눈에 들어오질 않습니다. 그 상태로 원핫인코딩을 진행한다면 카테고리마다 변수가 생겨 데이터가 sparse해지고, 트리 계열 모델을 학습한다면 학습 시간이 길어지면서 과적합되는 상황도 발생할 수 있을 것입니다. 위와 같은 단점을 해결하기 위해서는 해당 변수 내 카테고리 개수를 줄여야하는데..

문제 출처: https://dojang.io/mod/page/view.php?id=2433 파이썬 코딩 도장: 42.7 연습문제: 데코레이터로 매개변수의 자료형 검사하기 다음 소스 코드에서 데코레이터 type_check를 작성하세요. type_check는 함수의 매개변수가 지정된 자료형(클래스)이면 함수를 정상적으로 호출하고, 지정된 자료형과 다르면 RuntimeError 예외를 발생시 dojang.io 다음 소스 코드에서 데코레이터 type_check를 작성하세요. type_check는 함수의 매개변수가 지정된 자료형(클래스)이면 함수를 정상적으로 호출하고, 지정된 자료형과 다르면 RuntimeError 예외를 발생시키면서 '자료형이 다릅니다.' 에러 메시지를 출력해야 합니다. 여기서 type_chec..
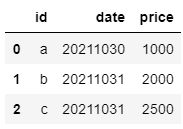
데이터 분석을 하다보면 파이썬에서 판다스 데이터프레임의 칼럼을 변경해야 하는 경우가 가끔 있습니다. 본 포스트에서는 칼럼 이름을 변경하는 방법에 대해 알아보겠습니다. 먼저 사용할 임의의 데이터프레임을 생성하겠습니다. import pandas as pd df = pd.DataFrame({'id': ['a', 'b', 'c'], 'date': ['20211030', '20211031', '20211031'], 'price': [1000, 2000, 2500]}) display(df) 칼럼명을 변경하는 방법은 크게 세 가지입니다. rename 메서드를 이용하는 방법, set_axis 메서드를 이용하는 방법, columns 어트리뷰트에 직접 할당하는 방법이 있는데요 하나씩 알아보겠습니다! 1. rename 메서..
제가 매일 까먹어서 작성합니다... 본 포스팅에서는 numpy의 서브모듈인 random을 이용하여 난수를 생성하는 방법을 알아보겠습니다. random은 난수를 발생시키는 모듈로 randint, hoice, randint, uniform 등의 메서드를 내장하고 있습니다. 아래 코드를 통해 로드한 후 사용하는데, 기본 모듈인 random과 혼동되지 않도록 주의하세요. from numpy import random 난수(亂數, Random Number)란 정의된 범위 내에서 무작위로 추출된 수를 일컫는다. 난수는 누구라도 그 다음에 나올 값을 확신할 수 없어야 한다. (출처: 위키백과) 1. seed 시드 설정을 할 때마다 동일한 숫자 세트가 나타나 코드 디버깅과 같은 작업을 할 때 유용하게 사용할 수 있습니다..
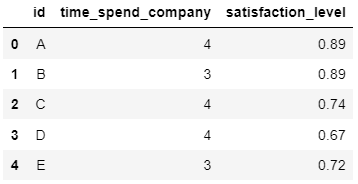
학생들의 시험점수를 이용해 등수를 매길 때, 고객이 가장 필요로 할 것 같은 상품의 우선순위를 따질 때 등 순위를 생성해야하는 상황은 다양합니다.. 본 포스트에서는 데이터프레임에 저장된 변수를 이용해 순위를 생성하는 방법을 알아보겠습니다. 사용할 데이터는 다음과 같습니다. import pandas as np import numpy as np sample = pd.DataFrame({'id': ['A', 'B', 'C', 'D', 'E'] , 'time_spend_company': [4, 3, 4, 4, 3] , 'satisfaction_level': [0.89, 0.89, 0.74, 0.67, 0.72]}) display(sample) 1. rank 함수 이용하기 rank 함수는 주어진 값들을 이용하여 ..
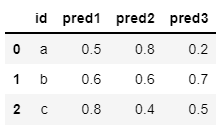
데이터 분석을 하다보면 필요에 따라 기존에 구성되어 있는 데이터를 재구조화하기도 합니다. 본 포스팅에서는 파이썬에서 데이터프레임을 재구성하는 방법, 특히 wide하게 구성되어 있는 데이터를 long하게 변경하는 방법에 대해 알아보겠습니다. wide 데이터는 가로로 놓여진 데이터를, long 데이터는 세로로 늘어놓인 데이터라는 것을 이해하고 읽으시면 좋겠습니다. 사용할 데이터는 다음과 같습니다. import pandas as pd df = pd.DataFrame({"id" : ['a', 'b', 'c'], "pred1" : [0.5, 0.6, 0.8], "pred2" : [0.8, 0.6, 0.4], "pred3" : [0.2, 0.7, 0.5]}) display(df) unique한 아이디마다 세 종류의..
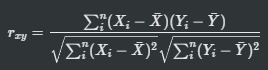
어떤 상품 X와 Y, Z가 있다고 합시다. 세 상품은 속성으로 제조년도, 제조국가, 유통기한, 소비기한, 원가, 판매가 등등을 가질 수 있겠죠. 이런 속성들을 숫자로 잘 뽑으면 상품들을 속성 값들의 나열, 즉 벡터로 표현할 수 있게 됩니다. 예를 들면, X = [1,0,2,3,2] Y = [1,0,3,2,1] Z = [0,1,3,1,1] 이런 식인거죠. 이렇게 아이템마다 벡터화를 해주고 나면, 아이템간 유사도를 구할 수 있습니다. 어떤 아이템이 과연 어떤 아이템과 가장 비슷한가? 혹은 비슷하지 않은가?를 계산할 수 있는 것이죠. 이 포스팅에서는 벡터를 이용하여 계산할 수 있는 유사도들을 알아보겠습니다. 1. 자카드 유사도(Jaccard Similarity) 자카드 유사도는 집합의 개념을 이용하는데요, 한..