들어가며
분석 과제를 하던 도중 범주형 변수를 숫자로 인코딩하기 위해 LabelEncoder가 필요하겠다 싶었습니다. 사용법을 확인하기 위해 사이킷런 공식문서를 살펴봤는데.. LabelEncoder는 타겟 변수 y를 하기 위해 사용하라고 써있더군요. label이 붙는 범주형 변수면 으레 사용 가능하다고 생각했었는데, 제가 오해를 하고 있었습니다. 공식문서를 다시금 잘 살펴보자는 교훈을 얻었네요.
이번 포스트는 LabelEncoder 와 OrdinalEncoder를 각각 소개하고 비교하고자 합니다. 두 인코더 모두 범주형 변수를 숫자로 인코딩하기 위해 쓰이는데요, LabelEncoder는 위에서 언급한 바와 같이 범주형 타겟 변수를, OrdinalEncoder는 범주형 입력 변수를 대상으로 합니다. 각각의 정의와 사용법을 확인하며 비교해보겠습니다.
데이터는 실험을 위해 간단하게 만들어 보았습니다.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder, OrdinalEncoder
data = pd.DataFrame(
{'contact': ['cellular', 'telephone', 'telephone', 'cellular', np.nan],
'loan': ['no', 'no', 'yes', 'yes', 'yes']}
)
display(data)
LabelEncoder 정의와 사용
LabelEncoder는 타겟 레이블(y)을 인코딩하기 위해 사용하는 클래스입니다. 보통 타겟 컬럼은 1차원이기 때문에 이 클래스는 입력으로 1차원 배열만을 받습니다. 때문에 변수를 두 개 이상 인코딩하고 싶은 경우에는 코드를 매번 새로 작성하거나 반복문을 사용해야겠죠.
le = LabelEncoder()
le.fit(data['contact'])
le.classes_
contact 변수를 인코딩한 후, classes를 확인해보았습니다. nan값까지 클래스로 취급하여 포함하고 있네요. 이제 인코딩한 정보를 가지고 다른 데이터에 transform을 적용해보겠습니다.
sample = pd.DataFrame(
{'contact': ['cellular', 'telephone', 'app', 'web', np.nan],
'loan': ['yes', 'yes', 'no', np.nan, 'unknown']}
)
le.transform(sample['contact'])
transform을 적용할 데이터에 인코딩 때에 보지 못했던 값들 app, web이 들어가 있기 때문에 에러가 발생합니다. 이를 해결하기 위해서는 직접 클래스 목록에 접근하여 클래스를 추가해줘야 합니다.
for label in sample['contact'].unique():
if label not in le.classes_:
le.classes_ = np.append(le.classes_, label)
sample['le_code'] = le.transform(sample['contact'])
display(sample[['contact', 'le_code']])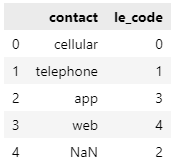
(공식문서의 정의와는 어긋나지만) 만약 여러 변수에 라벨인코더를 적용하고 싶다면, 반복문을 활용할 수 있겠습니다.
# fit
dict_le = dict()
for col in ['contact', 'loan']:
le = LabelEncoder()
le.fit(data[col])
dict_le[col] = le
# transform
for col in ['contact', 'loan']:
le = dict_le[col]
for label in sample[col].unique():
if label not in le.classes_:
le.classes_ = np.append(le.classes_, label)
sample[col + '_code'] = le.transform(sample[col])
display(sample[['contact', 'loan', 'contact_code', 'loan_code']])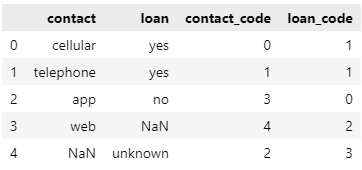
OrdinalEncoder 정의와 사용
OrdinalEncoder는 범주형 변수들(X)을 인코딩하기 위해 사용하는 클래스입니다. 여러 범주형 변수들을 한번에 입력으로 받을 수 있습니다.
oe = OrdinalEncoder()
oe.fit(data[['contact', 'loan']])
display(oe.categories_)
번거롭게 반복문을 사용하지 않고도 fit을 적용할 수 있습니다. 각 변수의 클래스들은 LabelEncoder처럼 classes_가 아닌, categories_를 통해 확인할 수 있습니다.
oe.transform(sample[['contact', 'loan']])
fit한 인코더로 transform을 시도했는데, LabelEncoder와 마찬가지로 에러가 발생합니다. OrdinalEncoder는 이런 경우를 처리하는 파라미터를 갖고 있습니다.
👉 unknown_value: transform을 수행할 때, fit한 당시에 보지 못했던 값을 어떤 값으로 처리할지를 정합니다.
👉 encoded_missing_value: 결측치를 어떤 값으로 처리할지를 정합니다.
oe = OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=99, encoded_missing_value=999)
oe.fit(data[['contact', 'loan']])
oe.transform(sample[['contact', 'loan']])
첫 번째 컬럼인 contact에서 app과 web은 fit 당시에 보지 못한 값이기 때문에 99로 처리되었으며, 5번째 값이었던 np.nan은 999로 처리된 것을 확인할 수 있습니다.
마치며
Label Encoder는 변수를 하나씩만 받기 때문에 변수마다 따로 인코딩을 해야하고, 이후 재사용을 위해 각각을 따로 저장해야 합니다. Ordinal Encoder를 사용하는 경우 이런 불편함을 해소할 수 있었죠. 한번에 여러 변수를 같이 입력으로 줄 수 있기 때문에 보다 편리하게 인코딩을 할 수 있습니다.
또한 Label Encoder는 fit 과정에서 보지 못했던 값이 transform 을 수행할 때 등장하는 경우, 에러를 발생시켰죠. 때문에 사용자가 직접 클래스에 접근하여 보지 못한 값을 처리하는 코드를 추가해야 했습니다. Ordinal Encoder는 보지 못한 값을 처리하는 파라미터를 사용하여 이를 처리할 수 있습니다. 이 파라미터는 보지 못한 값이 여러 개 등장하여도, 모두 동일한 값으로 처리한다는 점을 유의해야겠습니다.
지금까지 Label Encoder와 Ordinal Encoder의 정의와 사용 방법, 차이를 알아보았습니다. 분석 상황에 따라, 분석가의 선호에 따라 적절하게 인코더를 선택하여 적용하시길 바랍니다. 👍
참고
세바스찬 라시카, 바히드 미자리리, 「머신러닝 교과서」, 길벗
https://www.yes24.com/Product/Goods/98809693
머신 러닝 교과서 with 파이썬, 사이킷런, 텐서플로 - 예스24
아마존 머신 러닝 분야 베스트셀러! 그 명성 그대로!머신 러닝, 딥러닝 핵심 알고리즘에서 GAN, 강화 학습까지!코드 실행만으로는 머신 러닝과 딥러닝을 충분히 이해할 수 없다. 머신 러닝과 딥러
www.yes24.com
Difference between OrdinalEncoder and LabelEncoder
I was going through the official documentation of scikit-learn learn after going through a book on ML and came across the following thing: In the Documentation it is given about sklearn.preprocess...
datascience.stackexchange.com
sklearn.preprocessing.OrdinalEncoder
Examples using sklearn.preprocessing.OrdinalEncoder: Release Highlights for scikit-learn 1.3 Release Highlights for scikit-learn 1.2 Categorical Feature Support in Gradient Boosting Combine predict...
scikit-learn.org
'繩鋸木斷水滴石穿 > AI | 머신러닝' 카테고리의 다른 글
| [NLP] 감성 분석과 ABSA(Aspect-Based Sentiment Analysis) 개념 (1) | 2023.10.09 |
|---|---|
| [Tips] 범주형 변수의 카테고리 개수를 줄이는 방법들 (2) | 2023.09.10 |
| [모니터링] 2) 드리프트 감지 방법: KS 검정과 PSI (2) | 2023.05.28 |
| [모니터링] 1) model drift의 개념과 원인(data drift, label drift, concept drift) (0) | 2023.04.16 |
| [metric] 군집분석 평가 지표 1: 실루엣 계수(Silhouette Coefficient) (1) | 2023.03.24 |