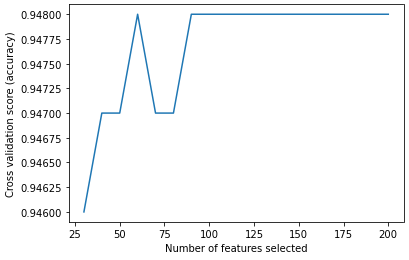
머신러닝으로 타겟을 예측하기 위해 수십, 수백개의 변수를 준비했습니다. 이 많은 변수들을 전부 머신러닝에 인풋 변수로 넣으면 최고의 성능이 나올까요? 항상 그렇지는 않습니다. 타겟과 연관성이 높은 변수도 있지만, 그 중에는 타겟을 예측하는 데에 혼선을 주는 변수들도 있을 수 있기 때문입니다. 게다가 입력변수가 너무 많으면 학습하는 속도도 느려지겠죠. 수집한 많은 변수들 중, 타겟을 예측할 때 유의미하게 사용될 수 있는 변수들을 분석가가 하나씩 살펴보며 취사선택할 수도 있지만 변수가 너무 많은 경우는 수작업이 어렵습니다.. 이때 사용하는 방법으로는 RFE(Recursive Feature Elimination)이 있습니다. RFE (Recursive Feature Elimination) RFE는 변수 선택 ..
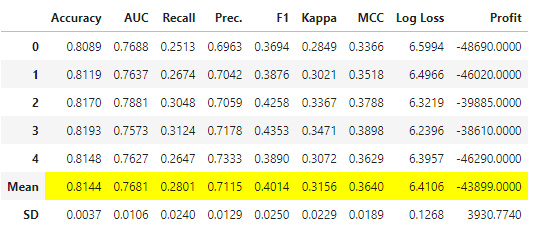
지난 포스트 pycaret 패키지를 이용한 분류모델 학습 (1) 에서는 머신러닝 학습을 위해 환경을 세팅하고, 평가지표를 추가하고, 다양한 모델을 학습하여 비교하는 실습을 했습니다. 이어서 본 포스트에서는 개별 모델 생성, 모델 튜닝, 모델을 이용해 예측하기, 모델 완성하고(finalize) 저장하기를 진행하겠습니다. 1) create_model 머신러닝 모델을 학습하고 Cross Validation을 이용해 검증을 진행하는 함수입니다. 분석가가 학습하고자 하는 알고리즘을 직접 지정하는데, 알고리즘에 적용하고 싶은 하이퍼파라미터도 직접 설정할 수 있습니다. 머신러닝 분석에 대한 방향성이 없을 때는 일단 적용할 수 있는 알고리즘들을 모두 적용해보는 compare_models 함수를 사용할 수 있겠습니다만,..

pycaret 이란 파이썬에서 작동하는 AutoML 오픈소스입니다. 단순한 코드 몇 줄로 머신러닝 모델을 쉽게 구현할 수 있습니다. 빠르게 피처 엔지니어링, 모델 학습, 하이퍼파라미터 튜닝, 예측을 포함하는 전체 프로세스를 실행할 수 있습니다. 어디서부터 머신러닝 프로젝트를 시작해야할지, 어떤 모델부터 구현해볼지 잘 모르겠을 때 pycaret을 이용해보면 좋을 것 같습니다. 🏭 AutoML 자동화된 머신러닝으로, 머신러닝 및 딥러닝 모델을 구축할 때 분석가는 AutoML에 학습 데이터만 제공하고 최적화된 모델을 제공받을 수 있다. (출처: https://www.itworld.co.kr/news/129362) 0) 설치 및 데이터 로드 !pip install pycaret 설치 후 사용할 라이브러리들을 불..
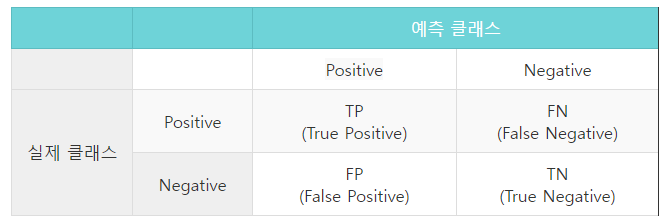
이진분류(binary classification)는 클래스가 0일지, 혹은 1일지를 맞추는 문제로, 실제 클래스와 예측 클래스의 조합에 따라 이진분류 모델의 성능을 정량화할 수 있습니다. 그 조합을 표로 나타낸 것을 혼동 행렬, 오차 행렬 또는 정오분류표(confusion matrix)이라고 하는데요. 아래와 같이 각 조합에 따라 실제 양성, 실제 음성, 거짓 양성, 거짓 음성으로 분류할 수 있습니다. 예측 클래스 Positive Negative 실제 클래스 Positive TP (True Positive) FN (False Negative) Negative FP (False Positive) TN (True Negative) TP(True Positive) 모델이 positive라고 예측했는데, 실제로..
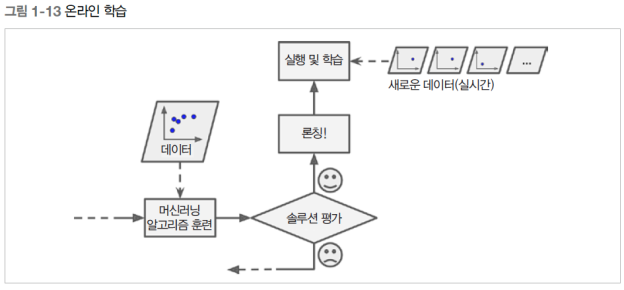
머신러닝은 입력 데이터의 스트림(stream)으로부터 점진적으로 학습할 수 있는지에 따라 배치학습 또는 온라인학습으로 분류될 수 있습니다. 아래에서 각각에 대해 알아보겠습니다. 1. 배치 학습(Batch Learning) = 오프라인 학습 시스템이 점진적으로 학습할 수 없는 학습입니다. 이용 가능한 데이터를 학습할 시점에 모두 사용하여 훈련시켜야 합니다. 시간과 자원을 많이 소모하므로 보통 오프라인에서 수행됩니다. 모델을 훈련시키고 적용하면 더 이상의 학습없이 실행됩니다. 새로운 데이터에 대해 학습하려면 새로운 데이터뿐만 아니라 이전 데이터도 모두 포함한 전체 데이터를 사용해 처음부터 다시 학습시켜야 합니다. 데이터를 업데이트하고 시스템의 새 버전을 서비스 운영에 필요한 만큼 자주 훈련시키면 됩니다. 다..
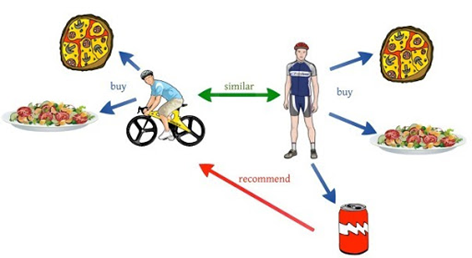
지난 추천시스템 3편에서는 컨텐츠 기반 필터링에 대해 알아보았습니다. 컨텐츠 기반 필터링은 아이템의 정보를 이용하여 과거에 사용자가 좋아했던 아이템과 유사한 다른 아이템을 추천하는 방식이죠. 본 포스팅에서는 컨텐츠 기반 필터링과 함께 널리 쓰이는 추천시스템인 협업필터링, 그 중 이웃기반 협업필터링에 대해 알아보겠습니다. 협업필터링(Collaborative Filtering) 먼저 협업 필터링이 무엇인지 다시 떠올려보겠습니다. 협업 필터링의 정의는 추천시스템 2편에서도 다룬 적이 있었는데요, '특정 상품에 대한 선호도가 유사한 고객들은 다른 상품에 대해서도 선호도가 비슷할 것이다’ 라는 가정하에 사용자의 아이템 평가 데이터를 이용해 비슷한 선호도를 갖는 다른 사용자가 선택한 아이템을 추천하는 방식을 협업 ..
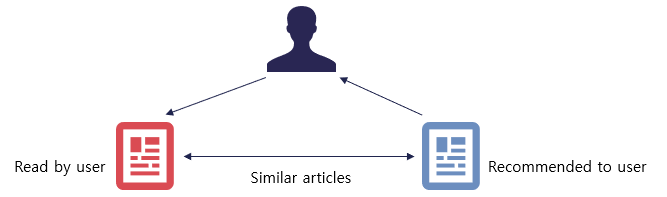
지난 추천시스템 2편에서는 추천시스템을 구축하기 위해 필요한 데이터의 종류와 대표적인 추천알고리즘을 간단하게 알아보았습니다. 본 포스팅에서는 널리 쓰이는 추천시스템 중 하나인 컨텐츠 기반 필터링에 대해 알아보겠습니다. 컨텐츠 기반 필터링(Contents-based Filtering) 아이템에 대한 프로필 데이터를 이용해 과거에 사용자가 좋아했던 아이템과 비슷한 유형의 아이템을 추천하는 시스템을 컨텐츠 기반 필터링이라고 합니다. 핵심은 사용자가 이전에 높은 평점을 주었던(좋았다고 평가했던) 아이템 A와 유사한 아이템 A'를 찾는 것이죠. 물론 이 아이템 A'는 사용자가 과거에 경험하지 않았던 아이템이어야 합니다. 예를 들어, 사용자가 영화 캡틴마블을 재밌게 보았다면 캡틴 마블에 대한 설명을 바탕으로 성격이..
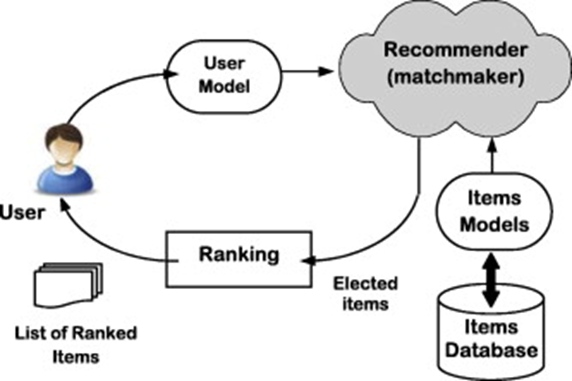
지난 추천시스템 1편에서 추천시스템의 여러 사례들과 개념을 간략하게 살펴보았습니다. 추천시스템이란 특정 사용자가에게 좋아할 것이라고 예상되는 상품을 추천하는 시스템이라고 언급했습니다. 사용자 입장에서는 원하는 정보를 찾는 데 들이는 시간을 줄일 수 있고, 기업 입장에서는 고객의 만족도를 높여 충성 고객을 확보할 수 있다는 장점이 있었습니다. 서비스가 다양해지고 정보도 넘쳐나는 IT 시대에 중요도가 더욱 부각되고 있는 머신러닝 알고리즘이라고 할 수 있죠. 이번 추천시스템 2편에서는 추천시스템을 구축하기 위해서 어떤 데이터가 필요한지, 그 데이터를 갖고 어떤 알고리즘을 적용해볼 수 있는지 알아보겠습니다. 추천시스템에서 사용하는 데이터 어떤 서비스든 머신러닝을 적용하기 위해서는 데이터가 필수로 갖춰져 있어야 ..
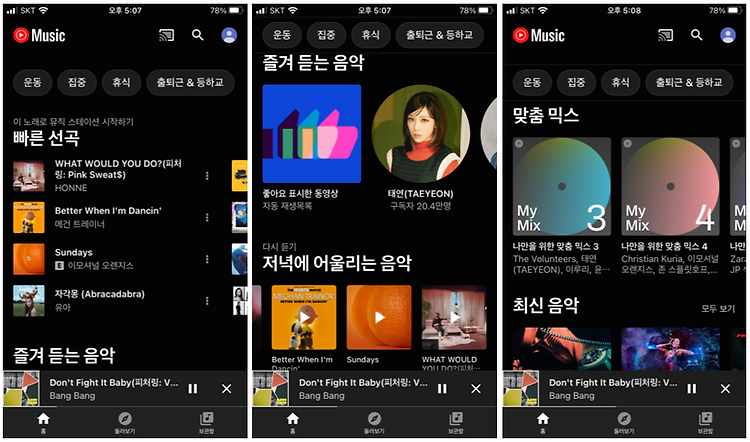
혹시 이 글을 보는 지금, 음악을 듣고 있진 않으신가요? 저는 이 글을 작성하는 지금 유튜브 뮤직을 이용해서 음악을 듣고 있습니다. 유튜브 뮤직의 메인 화면을 한번 같이 볼까요. 가장 위에는 제가 최근에 들었던 음악 목록을 제공하는데요, 저 음악 중 하나를 선택하면 노래가 재생되면서 유사한 곡들로 구성된 재생목록을 알아서 세팅해줍니다. 그 아래로는 즐겨 듣는 음악, (현재 저녁이기 때문에) 저녁에 어울리는 음악, 맞춤 믹스 재생목록 등을 사용자에게 제공해주고 있습니다. 차트100 처럼 현재 유행하는 곡을 보여주는 게 아니라 제가 자주 듣는 곡들을 보여주고 있죠. 인기곡, 인기뮤직미디오 같은 차트는 더 아래로 스크롤하거나, 아예 둘러보기 탭을 눌러야 접할 수 있습니다. 영화를 제공하는 대표적인 플랫폼인 왓..
grouplens에서 제공하는 movielens 데이터는 아래 사이트에서 다운받을 수 있습니다. 전체 데이터가 담겨있는 Full version과 이보다 적은 양의 데이터가 담겨있는 Small version이 준비되어 있는데요, Full version은 28만명의 사용자와 58000개의 영화 정보가 제공되고, Small version은 600명의 사용자와 9000개의 영화 정보가 제공된다고 합니다. 저장된 파일들의 형식은 동일하니 간단한 탐색을 위해 Full version 데이터가 아니라, Small version 데이터를 받아서 사용하겠습니다. https://grouplens.org/datasets/movielens/latest/ MovieLens Latest Datasets These datasets ..