grouplens에서 제공하는 movielens 데이터는 아래 사이트에서 다운받을 수 있습니다.
전체 데이터가 담겨있는 Full version과 이보다 적은 양의 데이터가 담겨있는 Small version이 준비되어 있는데요, Full version은 28만명의 사용자와 58000개의 영화 정보가 제공되고, Small version은 600명의 사용자와 9000개의 영화 정보가 제공된다고 합니다.
저장된 파일들의 형식은 동일하니 간단한 탐색을 위해 Full version 데이터가 아니라, Small version 데이터를 받아서 사용하겠습니다.
https://grouplens.org/datasets/movielens/latest/
MovieLens Latest Datasets
These datasets will change over time, and are not appropriate for reporting research results. We will keep the download links stable for automated downloads. We will not archive or make available p…
grouplens.org
ml-latest-small.zip 파일을 다운로드받아 압축을 풀면 다음과 같은 파일들이 있는 것을 확인할 수 있습니다. 이 중 movies.csv, ratings.csv, tags.csv를 중점적으로 살펴볼게요.

import os
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
path = 'csv가 저장된 경로'
movies_df = pd.read_csv(os.path.join(path + 'movies.csv'), index_col='movieId', encoding='utf-8')
ratings_df = pd.read_csv(os.path.join(path + 'ratings.csv'), encoding='utf-8')
tags_df = pd.read_csv(os.path.join(path + 'tags.csv'), encoding='utf-8')
movies.csv
영화 정보가 담긴 데이터는 movies.csv 입니다. 각 영화의 아이디가 데이터프레임의 인덱스로 할당되어 있고, 칼럼으로 타이틀(title)과 장르(genres)를 갖고 있습니다.
print(movies_df.shape)
movies_df.head()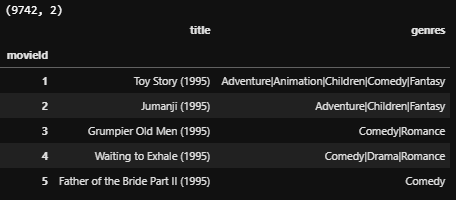
타이틀 칼럼에는 영화의 제목과 연도가 표시되어 있는데요, 이 칼럼으로부터 연도를 추출하고 싶다면 정규표현식과 replace 함수를 사용하여 다음과 같이 해볼 수 있겠습니다.
movies_df['year'] = movies_df['title'].str.extract('(\(\d\d\d\d\))')
movies_df['year'] = movies_df['year'].apply(lambda x: x.replace('(','').replace(')',''))
movies_df.head()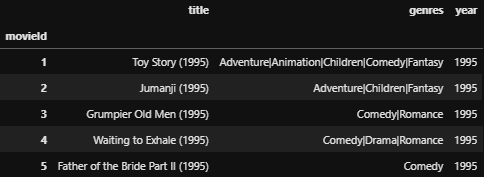
그리고 장르 칼럼에는 해당 영화가 담고 있는 장르가 저장되어 있는데요, 각 장르는 |(bar)로 구분되어 있습니다. 어떤 장르들이 포함되어 있는지 확인해보겠습니다.
all_genres = [x.split('|') for x in movies_df['genres'].values]
all_genres[:5][['Adventure', 'Animation', 'Children', 'Comedy', 'Fantasy'],
['Adventure', 'Children', 'Fantasy'],
['Comedy', 'Romance'],
['Comedy', 'Drama', 'Romance'],
['Comedy']]|(bar)로 구분된 장르들은 문자이기 때문에 split 함수를 이용하여 분리한 후, 각각을 리스트 내 원소로 저장할 수 있습니다. all_genres를 보면 영화마다 해당하는 장르들을 리스트로 저장한 것을 확인할 수 있습니다.
import itertools
genres = list(set(list(itertools.chain(*all_genres))))
print(len(genres)) # 20
print(genres)20
['Romance', 'War', 'Horror', 'Fantasy', 'Adventure', 'Mystery', 'Musical', '(no genres listed)', 'Thriller', 'Crime', 'Children', 'Animation', 'Western', 'Action', 'Drama', 'Film-Noir', 'IMAX', 'Documentary', 'Comedy', 'Sci-Fi']유니크한 장르의 개수를 세기 위해서 itertools를 사용하였습니다. itertools 모듈 내 chain 함수를 이용해 list in list의 원소들을 전부 풀고, set을 적용하면 중복을 제거하여 유일한 값들만 남길 수 있습니다.
프린트된 값을 보니 유니크한 장르는 총 20개가 있고, 'Romance', 'War', 'Musical' 등이 값으로 존재하고 있네요. 만약 small version 이 아닌 full version의 데이터를 불러온다면 이보다 더 많은 장르가 포함되어 있을 수도 있겠죠.
이제 영화마다 위 20개 장르들을 포함하는지 여부를 0, 1로 나타내고 싶다고 합시다. pandas의 get_dummies 함수를 적용하면 쉽게 확인이 가능합니다. 장르들이 |(bar)로 구분되어 있으니 구분자로 지정을 해주고 실행하면 다음과 같은 결과를 확인할 수 있습니다.
genres_df = movies_df['genres'].str.get_dummies(sep='|')
genres_df.head()
ratings.csv
사용자마다 관람한 영화에 대해 평점을 남긴 데이터는 ratings.csv에 저장되어 있습니다. 사용자들이 모든 영화를 관람하지는 않기 때문에 (사용자 수 x 영화 수)만큼 데이터가 존재하지는 않습니다.
print(ratings_df.shape)
ratings_df.head()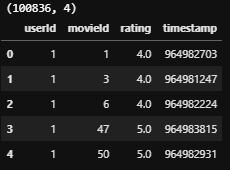
평점(rating 칼럼)의 평균과 표준편차를 확인해볼게요.
print('평점의 평균: ', ratings_df['rating'].mean().round(4))
print('평점의 표준편차: ', ratings_df['rating'].std().round(4))평점의 평균: 3.5016
평점의 표준편차: 1.0425평점의 평균은 3.5점이고, 대체로 사용자들은 2.5점에서 4.5점 사이의 점수를 준다는 것을 알 수 있습니다. 히스토그램으로 빈도도 살펴볼게요.
ratings_df.rating.hist()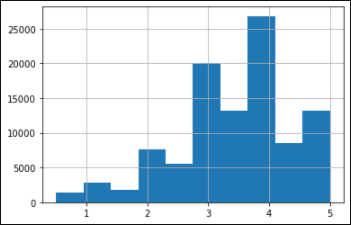
평점은 약간 오른쪽으로 치우친 경향을 보이네요. 4점 근처의 점수가 많고, 2점 아래로 평가되는 경우는 상대적으로 적어보입니다.
추천시스템을 구축하게 된다면, 이 평점 데이터로부터 사용자별(혹은 영화별)로 평균 평점을 추출한다거나, 사용자가 관람한 영화 개수를 추출하여 추가 정보로 사용할 수도 있겠습니다.
tags.csv
tags.csv에는 사용자가 영화를 관람한 후 남긴 리뷰로부터 추출된 태그가 저장되어 있습니다. 자연어 처리 등을 이용해서 사용자별(혹은 영화별) 어떤 태그들이 속해있는지, 어떤 속성의 태그들이 많이 포함되어있는지 확인하고 추천 시스템에 정보로 활용할 수도 있겠습니다. word2vec과 같은 word representation 기법을 이용해 단어, tag를 벡터로 나타낸 후에 평점을 예측하기 위한 input data로 활용한다면 더 정확도가 높은 추천 시스템을 만들 수도 있겠죠.
print(tags_df.shape)
tags_df.head()
이상 추천 시스템 구축에서 예시로 절대! 빠지지 않는 무비렌즈 데이터를 탐색해보았습니다. 이외에도 다양한 데이터셋이 오픈되어 있으니 추천알고리즘에 관심이 있으시다면 이 사이트에서 한번 확인하시고 여러 알고리즘을 적용해보시기를 바랍니다.
https://analyticsindiamag.com/10-open-source-datasets-one-must-know-to-build-recommender-systems/
10 Datasets One Must Know To Build Recommender Systems
Be it watching a web series or shopping online, recommender systems work as time-savers for many. Here are ten datasets to build recommender systems.
analyticsindiamag.com
참고
https://github.com/jaewonlee-728/fastcampus-RecSys/tree/master/01-Recommender-System-101
jaewonlee-728/fastcampus-RecSys
2020 패스트캠퍼스 추천시스템 A to Z. Contribute to jaewonlee-728/fastcampus-RecSys development by creating an account on GitHub.
github.com
'繩鋸木斷水滴石穿 > AI | 머신러닝' 카테고리의 다른 글
| 배치 학습(오프라인 학습)과 온라인 학습 비교 (0) | 2022.03.15 |
|---|---|
| [추천시스템] 4) 협업필터링 - 이웃기반 협업필터링 (0) | 2021.10.16 |
| [추천시스템] 3) 컨텐츠 기반 필터링(Contents-based Filtering) (1) | 2021.09.11 |
| [추천시스템] 2) 사용하는 데이터와 추천알고리즘의 종류 (0) | 2021.07.10 |
| [추천시스템] 1) 추천시스템이란? - 사례와 개념 (0) | 2021.06.26 |