pycaret 이란

파이썬에서 작동하는 AutoML 오픈소스입니다. 단순한 코드 몇 줄로 머신러닝 모델을 쉽게 구현할 수 있습니다. 빠르게 피처 엔지니어링, 모델 학습, 하이퍼파라미터 튜닝, 예측을 포함하는 전체 프로세스를 실행할 수 있습니다. 어디서부터 머신러닝 프로젝트를 시작해야할지, 어떤 모델부터 구현해볼지 잘 모르겠을 때 pycaret을 이용해보면 좋을 것 같습니다.
🏭 AutoML
자동화된 머신러닝으로, 머신러닝 및 딥러닝 모델을 구축할 때 분석가는 AutoML에 학습 데이터만 제공하고 최적화된 모델을 제공받을 수 있다.
(출처: https://www.itworld.co.kr/news/129362)
0) 설치 및 데이터 로드
!pip install pycaret
설치 후 사용할 라이브러리들을 불러옵니다.
import os
import sys
from datetime import datetime
import pickle
from pycaret.datasets import get_data
from pycaret.classification import *
import optuna본 예제에서는 분류 모델을 학습할 거라서 pycaret.classification 모듈을 import 했습니다.
회귀 모델을 학습한다면 pycaret.regression, 비지도 학습을 진행한다면 pycaret.clustering을 불러옵니다. 더 많은 서브모듈들은 공식 깃허브를 통해 확인하세요.
사용할 데이터는 채무 불이행 여부(0 또는 1)에 대한 정보로, 채무 불이행 여부를 예측하기 위해 성별, 학력, 나이, n개월 전 상환 여부 등을 예측 변수로 사용합니다.
# load data
data = get_data('credit')
display(data.shape)
1) set up
setup은 학습에 필요한 모든 환경을 초기화하는 단계로, 학습 전에 반드시 수행되어야 합니다.
학습/평가 데이터 분할 비율, 타겟 변수, seed값, GPU 사용여부, CV fold 수 등을 정합니다.
다양한 파라미터와 디폴트 값에 대한 정보는 여기서 확인하세요.
exp_clf101 = setup(data=data,
target='default',
fold=5,
session_id=123)위 코드를 실행하고 나면 아래와 같이 pycaret이 추정한 칼럼별 데이터 타입을 보여줍니다.

그리고 분석가에게 추정된 타입으로 계속 진행할지를 물어봅니다. 분석가가 의도한 데이터 타입이 모두 맞다면 아래 칸에서 엔터를 치고, 틀리게 추정된 칼럼이 있다면 'quit'을 작성해 코드실행을 중단할 수도 있습니다.(AutoML이면 알아서 해야 되는거 아님? 알아서 해!! 하시는 분들은 silent=True를 설정하세요)
2) add_metrics
비즈니스에서 머신러닝을 적용할 때, 일반적으로 사용하는 평가지표들 외에 다른 지표들을 사용하여 모델을 평가하고 싶은 경우도 있습니다. 그냥 있는 거 쓰면 편하겠지만.. 비즈니스는 그렇게 호락호락하지 않은가 봅니다. 직접 평가지표를 추가하고 싶은 경우에는 add_metric 함수를 사용할 수 있습니다. sklearn과 같은 머신러닝 전문 라이브러리에서 제공하는 지표를 가져와서 등록할 수도 있고, 사용자가 직접 함수를 정의하여 등록할 수도 있습니다.
# 1) 이미 존재하는 metric을 가져와 추가하는 경우
# sklearn에서 제공하는 metric인 log loss를 평가지표로 추가
from sklearn.metrics import log_loss
add_metric('logloss', # id
'Log Loss', # name
log_loss, # 함수
greater_is_better=False # 함수 결과값이 커야 좋은가?
)# 2) 평가지표를 직접 함수로 정의하는 경우
# 사용자 정의 함수는 y와 y_pred를 받아 metric을 계산함
def calculate_profit(y, y_pred):
tp = np.where((y_pred==1) & (y==1), (120-15), 0)
fp = np.where((y_pred==1) & (y==0), -15, 0)
fn = np.where((y_pred==0) & (y==1), -120, 0)
return np.sum([tp, fp, fn])
# add metric to PyCaret
add_metric('profit', 'Profit', calculate_profit, greater_is_better=True)
get_metrics 함수를 통해 기존에 제공하고 있는 평가지표들과 분석가가 정의한 평가지표들을 확인할 수 있습니다. 분류 문제의 경우 pycaret은 Accuracy, AUC, Recall, Precision, F1, Kappa, MCC를 기본으로 제공해주고 있네요.
(Accuracy, Recall, Precision, F1를 알고 싶다면 여기)
get_metrics() # 사용될 평가지표 확인
3) compare_models
AutoML의 가장 강력한 기능인 모델 비교입니다. 내부적으로 Cross Validation을 이용해 기본적으로 제공하는 모든 모델들을 학습하고 평가한 후, 성능이 가장 우수한 모델을 반환해줍니다. 학습에 사용할 수 있는 모델 후보들은 models() 함수를 이용해 확인할 수 있습니다.(파이썬에 설치된 라이브러리에 따라 목록에 보여지는 모델이 다를 수 있습니다. 필요한 경우 직접 모델 라이브러리를 설치하시고 다시 확인해보면 리스트에 나타날 거예요)
models()
모델 비교는 compare_models 함수를 이용합니다. 위에서 확인한 바와 같이 학습에 여러 모델을 사용할 수 있지만, 이 중 일부만 선택하여 모델 비교를 진행할 수도 있습니다. 또한 가장 성능이 우수한 모델을 선택할 때 원하는 성능지표가 가장 좋게 나타난 모델을 선택하도록 성능지표를 변경할 수도 있습니다(디폴트로 정확도를 사용합니다). 자세한 파라미터 설명은 여기서 확인해주세요.
이 예시에서는 정확도가 가장 높은 하나의 모델만을 선택하여 반환하도록 하였습니다.
best_model = compare_models()
함수를 실행하고 나면 성능지표별로 가장 우수한 점수를 노란색으로 표시해줍니다. 최고의 모델을 선택하는 데 이용할 성능지표 결과를 정렬해서 보여주기까지 하죠. 화면상에 값이 잘 안보여서ㅎ pull을 이용해 결과를 새로 저장하고 살펴볼게요.
result = pull()
display(result)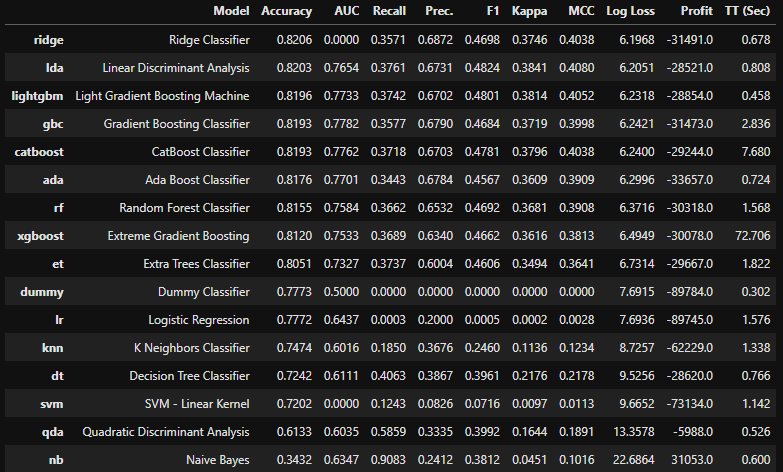
릿지 모델이 정확도가 0.82로 가장 높았고, 선형판별분석(Linear Discriminant Analysis)이 그 뒤를 이었습니다. 릿지 모델은 정확도가 가장 높긴 했지만 AUC가 0으로 굉장히 이상한 결과를 보여주네요.. 이래서 하나의 평가지표만을 이용해 모델을 선택해서는 안되는 것 같습니다.😅
아무튼 best_model은 정확도가 가장 높게 나타난 릿지 모델이 선정되었네요.
만약 성능이 높았던 여러 모델을 blend 혹은 stack 하여 최종 모델을 만든다면, 모델 비교를 할 때 여러 모델을 선택하는 n_select 파라미터를 변경하여 실험을 진행할 수도 있습니다.
best_modelRidgeClassifier(alpha=1.0, class_weight=None, copy_X=True, fit_intercept=True,
max_iter=None, normalize=False, random_state=123, solver='auto',
tol=0.001)
이상 본 포스트에서 실험환경 설정(setup), 성능지표 추가하기(add_metrics), 모델 비교하기(compare_models)에 대해 알아보았습니다.
다음 포스트에서는 개별 모델 생성(create_model), 하이퍼파라미터 튜닝(tune_model), 예측(predict_model)하는 방법에 대해 알아보겠습니다.
참고
https://pycaret.gitbook.io/docs/
Welcome to PyCaret - PyCaret Official
Compared with the other open-source machine learning libraries, PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with few lines only. This makes experiments exponentially fast and efficient. PyCaret is essentia
pycaret.gitbook.io
https://github.com/pycaret/pycaret
GitHub - pycaret/pycaret: An open-source, low-code machine learning library in Python
An open-source, low-code machine learning library in Python - GitHub - pycaret/pycaret: An open-source, low-code machine learning library in Python
github.com
'繩鋸木斷水滴石穿 > AI | 머신러닝' 카테고리의 다른 글
| RFE와 REFCV: 유의미한 변수를 선택하는 방법 (1) | 2022.07.17 |
|---|---|
| [AutoML] pycaret 패키지를 이용한 분류모델 학습 (2) create_model, tune_model, predict_model, finalize_model (1) | 2022.04.24 |
| 이진분류 모형평가 방법: confusion matrix와 정확도, 재현율, 정밀도, F1 score (1) | 2022.03.20 |
| 배치 학습(오프라인 학습)과 온라인 학습 비교 (0) | 2022.03.15 |
| [추천시스템] 4) 협업필터링 - 이웃기반 협업필터링 (0) | 2021.10.16 |