지난 추천시스템 3편에서는 컨텐츠 기반 필터링에 대해 알아보았습니다. 컨텐츠 기반 필터링은 아이템의 정보를 이용하여 과거에 사용자가 좋아했던 아이템과 유사한 다른 아이템을 추천하는 방식이죠. 본 포스팅에서는 컨텐츠 기반 필터링과 함께 널리 쓰이는 추천시스템인 협업필터링, 그 중 이웃기반 협업필터링에 대해 알아보겠습니다.
협업필터링(Collaborative Filtering)
먼저 협업 필터링이 무엇인지 다시 떠올려보겠습니다. 협업 필터링의 정의는 추천시스템 2편에서도 다룬 적이 있었는데요, '특정 상품에 대한 선호도가 유사한 고객들은 다른 상품에 대해서도 선호도가 비슷할 것이다’ 라는 가정하에 사용자의 아이템 평가 데이터를 이용해 비슷한 선호도를 갖는 다른 사용자가 선택한 아이템을 추천하는 방식을 협업 필터링이라고 했습니다.
예를 들어 영화 겨울왕국1에 대한 평가가 유사한 두 사람에게, 어느 한쪽이 아직 시청하지 않았지만 다른 사림이 좋은 평가를 내린 영화 겨울왕국2를 추천하는 식입니다.
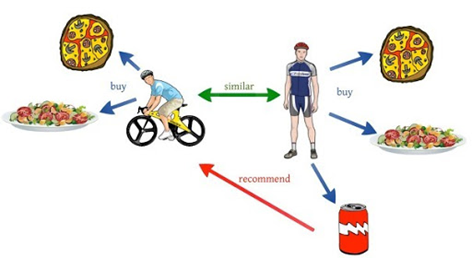
협업 필터링은 잠재적인 고객 선호도를 추정하여 다양한 상품을 추천할 수 있게 합니다. 사용자가 본인도 몰랐던 새로운 취향을 발견할 수 있겠죠. 하지만 사용자나 아이템의 특징을 사용하지 않기 때문에 사용자와 아이템의 interaction 데이터가 충분히 갖춰져야 시도할 수 있습니다. 새로운 상품이나 고객이 추가되면 관련 정보가 없기 때문에 추천이 불가능한 cold-start 문제도 갖고 있고, 고객 수나 아이템 수가 너무 많으면 아이템을 구매한 고객 비율이 매우 적어져 추정된 선호도가 정확하지 않을 수도 있다는 단점도 있습니다.
협업 필터링은 크게 이웃기반 협업 필터링(또는 메모리기반 협업필터링)과 모델기반 협업필터링(또는 잠재요인 협업필터링)으로 나누어져있는데요, 이번 포스트에서는 이웃기반 협업필터링만 다루겠습니다.
이웃기반 협업필터링(Neighbor based Collaborative Filtering)
이웃기반 협업필터링은 사용자가 아이템에 대하여 남긴 평점 데이터를 이용하여 아직 평점을 남기지 않은 아이템들에 대해 예측을 수행하고, 예측 평점이 높은 N개의 아이템을 추천하는 방식입니다. 평점 데이터는 아래 그림과 같이 행은 사용자 인덱스, 열은 아이템 인덱스를 갖는 행렬로 구성할 수 있겠습니다. 사용자가 과거에 경험한 아이템에 대해 평가를 하고, 경험하지 않은 아이템은 빈 값으로 두는 것이죠. 이 빈 값을 채워서 예상 평점을 높게 받은 아이템을 추천합니다. 몇 개의 아이템을 추천할지는 추천 시스템을 적용할 플랫폼의 환경을 고려하여 결정하거나 혹은 비즈니스 관점에서 결정할 수 있겠죠.

이웃기반 협업필터링은 어떤 것끼리 유사도를 계산할 것인가?를 기준으로 사용자 기반(User-based) 협업필터링과 아이템 기반(Item-based) 협업필터링으로 나눌 수 있습니다.

(A) 사용자 기반 협업 필터링(User-based Collaborative Filtering)
사용자 기반 협업 필터링은 우선 사용자간 유사도를 계산합니다. 사용자간 유사도를 추정해보니 사용자 B와 사용자 D가 유사한 사용자로 판명이 났어요. 그럼 사용자 B가 사용했지만 사용자 D는 사용하지 않은 아이템 7번을 사용자 D에게 추천해주는 것입니다.
(B) 아이템 기반 협업 필터링(Item-based Collaborative Filtering)
아이템 기반 협업 필터링은 아이템간 유사도를 계산합니다. 아이템간 유사도를 추정해보니 아이템 2번과 아이템 4번이 유사하다고 나타난 거죠. 그럼 아직 아이템 4번을 사용하지 않은 사용자 E에게 아이템 4번을 추천해주는 것입니다.
사용자 기반 협업 필터링 계산 예시
| 아이템 1번 | 아이템 2번 | 아이템 3번 | 아이템 4번 | 아이템 5번 | |
| 사용자 A | 5 | 4 | 4 | 3 | |
| 사용자 B | 1 | 0 | 1 | 4 | |
| 사용자 C | 4 | 4 | 5 | 3 | |
| 사용자 D | 2 | 1 | 4 | 3 | |
| 사용자 E | 4 | 4 | 4 | 2 | |
| 사용자 F | 4 | 2 | 3 | 1 |
사용자가 아이템에 대해 평가한 데이터가 위와 같이 주어져 있다고 하겠습니다. 사용자 A ~ F가 아이템 1번 ~ 5번에 대해 0점에서 5점 사이의 점수를 주었습니다. 평가하지 않은 아이템은 빈 값으로 두었구요.
먼저, 사용자간 유사도를 계산합니다. 예를 들어 사용자 B와 사용자 D가 얼마나 유사한지를 코사인 유사도를 사용하여 계산하면 아래와 같이 계산이 되겠죠.

사용자 B와 사용자 D가 함께 평가한 아이템 2번, 3번 그리고 5번의 평점만을 이용하여 유사도를 계산한 결과, 0.84로 매우 유사하다고 나타났습니다. 이렇게 모든 사용자들끼리의 유사도를 계산하여 사용자 유사도 행렬을 완성합니다.
(💁♀️ 유사도의 종류를 알고 싶다면? -> 유사도의 종류와 파이썬 구현 포스트를 참고하세요)
| 사용자 A | 사용자 B | 사용자 C | 사용자 D | 사용자 E | 사용자 F | |
| 사용자 A | 1.00 | 0.84 | 0.96 | 0.82 | 0.98 | 0.98 |
| 사용자 B | 0.84 | 1.00 | 0.61 | 0.84 | 0.63 | 0.47 |
| 사용자 C | 0.96 | 0.61 | 1.00 | 0.97 | 0.99 | 0.92 |
| 사용자 D | 0.82 | 0.84 | 0.97 | 1.00 | 0.85 | 0.71 |
| 사용자 E | 0.98 | 0.63 | 0.99 | 0.85 | 1.00 | 0.98 |
| 사용자 F | 0.98 | 0.47 | 0.92 | 0.71 | 0.98 | 1.00 |
전체 사용자 간의 유사도를 계산하면 위와 같이 사용자 유사도 행렬을 얻을 수 있습니다. 자기 자신과의 유사도는 1.0이고, 행과 열의 인덱스가 동일하기 때문에 대각원소를 기준으로 대칭인 것을 확인할 수 있습니다.
이제 이 사용자 유사도 행렬을 바탕으로 사용자 B가 아이템 4번에 내릴 평점을 예측해보겠습니다. 점수를 예측하는 방식에도 여러 방법이 있는데, 여기서는 모든 사용자의 점수를 이용해 가중합을 구하는 방식으로 계산해보겠습니다. 아이템 4번에 평가를 내렸던 사용자 A, C, D, E의 평점과 사용자 B와 A, C, D, E의 유사도를 이용하여 가중합을 구하면 아래와 같습니다. 사용자 F는 아이템 4번에 평가하지 않았기 때문에 계산에 이용하지 않습니다.

사용자 B는 아이템 4번에 대해서 3.92점을 줄 것으로 예측되었습니다. 5점이 최고점인 것을 생각하면 나름 높은 점수를 줄 것으로 예상한 거죠.
이런 방식으로 사용자-아이템 평가 행렬을 채우고, 높은 점수를 받은 아이템들을 선별하여 사용자에게 추천합니다. 높은 점수를 받은 아이템 중 사용자가 이미 경험했던 아이템은 제외하고 추천할 아이템을 줄세우기하여 사용자에게 제공하면 추천 시스템이 완성됩니다.
이상으로 협업 필터링 중 이웃기반 협업 필터링에 대해 알아보았습니다. 협업 필터링과 이웃기반 협업 필터링의 정의를 살펴보았고, 이웃기반 협업 필터링에 속하는 사용자 기반과 아이템 기반에 대해 알아보았습니다. 보통 사용자 수가 아이템 수보다 훨씬 많기 때문에 사용자 간의 유사도를 구하는 비용이 더 많이 든다고 해요. 그래서 사용자 유사도 행렬을 구하는 것보다 아이템 유사도 행렬을 구하는 아이템 기반 협업필터링이 널리 쓰인다고 알려져 있습니다. 실제로 세계 최대 온라인 쇼핑몰인 아마존은 아이템 기반 추천을 실행한다고 하네요. 각자의 비즈니스 상황을 파악하고 적절한 협업 필터링을 적용하면 빠르고 성능 좋은 추천 시스템을 구축할 수 있을 것 같습니다.
다음 포스트에서는 이웃기반 협업 필터링과 함께 협업 필터링에 속하는 모델기반 협업필터링에 대해 알아보겠습니다.
'繩鋸木斷水滴石穿 > AI | 머신러닝' 카테고리의 다른 글
| 이진분류 모형평가 방법: confusion matrix와 정확도, 재현율, 정밀도, F1 score (1) | 2022.03.20 |
|---|---|
| 배치 학습(오프라인 학습)과 온라인 학습 비교 (0) | 2022.03.15 |
| [추천시스템] 3) 컨텐츠 기반 필터링(Contents-based Filtering) (1) | 2021.09.11 |
| [추천시스템] 2) 사용하는 데이터와 추천알고리즘의 종류 (0) | 2021.07.10 |
| [추천시스템] 1) 추천시스템이란? - 사례와 개념 (0) | 2021.06.26 |