
9월 초 즈음이었나 길을 걷다가 눈에 띈 포스트가 있었습니다. 바로 서울도시건축비엔날레를 알리는 포스트였는데요, 재밌을 것 같은데 가봐야겠다 생각만 하다가 오늘 드디어 서울도시건축전시관과 세운상가에 방문해 관람하였습니다. 2021 서울도시건축비엔날레 기간: 2021년 9월 16일 ~ 10월 31일 장소: 동대문디자인플라자, 서울도시건축전시관, 세운상가 일대 주제: 크로스로드, 어떤 도시에 살 것인가 지금 우리는 급속한 성장과 무분별한 도시 개발 시대를 지나, 느리지만 지속적인 성장의 시대 그리고 포용성이 필요한 시대로 접어들었다. 여전히 대량 공급되는 부동산 개발에 대한 욕구와 수요가 있지만 동시에 각자의 다른 삶을 반영하는 공간, 동네 건축에 대한 관심도 증가하고 있다. 이러한 전환과 가치 공존의 시대..
제가 매일 까먹어서 작성합니다... 본 포스팅에서는 numpy의 서브모듈인 random을 이용하여 난수를 생성하는 방법을 알아보겠습니다. random은 난수를 발생시키는 모듈로 randint, hoice, randint, uniform 등의 메서드를 내장하고 있습니다. 아래 코드를 통해 로드한 후 사용하는데, 기본 모듈인 random과 혼동되지 않도록 주의하세요. from numpy import random 난수(亂數, Random Number)란 정의된 범위 내에서 무작위로 추출된 수를 일컫는다. 난수는 누구라도 그 다음에 나올 값을 확신할 수 없어야 한다. (출처: 위키백과) 1. seed 시드 설정을 할 때마다 동일한 숫자 세트가 나타나 코드 디버깅과 같은 작업을 할 때 유용하게 사용할 수 있습니다..

긴 연휴가 시작된 지난 토요일, 세종에 위치한 국립세종수목원을 방문했습니다. 본가에 내려간 김에 전부터 가보고 싶었던 수목원에 갈 계획을 세웠고, 전날에 미리 예약도 마쳤습니다.(수목원 내 사계절전시온실을 방문하고 싶다면 홈페이지에서 예약하셔야 되고, 온실을 방문하지 않을 경우 현장 발매를 하셔도 됩니다!) 국립세종수목원은 약 20만평의 면적을 갖춘 국내 첫 도심형 수목원인데요, 사계절전시온실, 한국전통정원, 분재원 등 다양한 테마를 가진 전시원이 마련되어 있고 약 2800종의 식물을 관람할 수 있습니다. 저는 입구인 방문자센터를 거쳐 사계절전시온실 - 한국전통정원 - 분재전시관 - 어린이정원 - 희귀특산식물전시온실 - 습지원 - 생활정원 순으로 관람하였습니다. 면적이 상당한 만큼 어딜 가봐야할지 고민된..
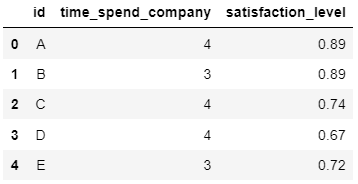
학생들의 시험점수를 이용해 등수를 매길 때, 고객이 가장 필요로 할 것 같은 상품의 우선순위를 따질 때 등 순위를 생성해야하는 상황은 다양합니다.. 본 포스트에서는 데이터프레임에 저장된 변수를 이용해 순위를 생성하는 방법을 알아보겠습니다. 사용할 데이터는 다음과 같습니다. import pandas as np import numpy as np sample = pd.DataFrame({'id': ['A', 'B', 'C', 'D', 'E'] , 'time_spend_company': [4, 3, 4, 4, 3] , 'satisfaction_level': [0.89, 0.89, 0.74, 0.67, 0.72]}) display(sample) 1. rank 함수 이용하기 rank 함수는 주어진 값들을 이용하여 ..
지난 추천시스템 2편에서는 추천시스템을 구축하기 위해 필요한 데이터의 종류와 대표적인 추천알고리즘을 간단하게 알아보았습니다. 본 포스팅에서는 널리 쓰이는 추천시스템 중 하나인 컨텐츠 기반 필터링에 대해 알아보겠습니다. 컨텐츠 기반 필터링(Contents-based Filtering) 아이템에 대한 프로필 데이터를 이용해 과거에 사용자가 좋아했던 아이템과 비슷한 유형의 아이템을 추천하는 시스템을 컨텐츠 기반 필터링이라고 합니다. 핵심은 사용자가 이전에 높은 평점을 주었던(좋았다고 평가했던) 아이템 A와 유사한 아이템 A'를 찾는 것이죠. 물론 이 아이템 A'는 사용자가 과거에 경험하지 않았던 아이템이어야 합니다. 예를 들어, 사용자가 영화 캡틴마블을 재밌게 보았다면 캡틴 마블에 대한 설명을 바탕으로 성격이..
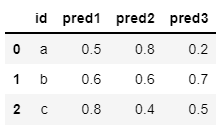
데이터 분석을 하다보면 필요에 따라 기존에 구성되어 있는 데이터를 재구조화하기도 합니다. 본 포스팅에서는 파이썬에서 데이터프레임을 재구성하는 방법, 특히 wide하게 구성되어 있는 데이터를 long하게 변경하는 방법에 대해 알아보겠습니다. wide 데이터는 가로로 놓여진 데이터를, long 데이터는 세로로 늘어놓인 데이터라는 것을 이해하고 읽으시면 좋겠습니다. 사용할 데이터는 다음과 같습니다. import pandas as pd df = pd.DataFrame({"id" : ['a', 'b', 'c'], "pred1" : [0.5, 0.6, 0.8], "pred2" : [0.8, 0.6, 0.4], "pred3" : [0.2, 0.7, 0.5]}) display(df) unique한 아이디마다 세 종류의..
어떤 상품 X와 Y, Z가 있다고 합시다. 세 상품은 속성으로 제조년도, 제조국가, 유통기한, 소비기한, 원가, 판매가 등등을 가질 수 있겠죠. 이런 속성들을 숫자로 잘 뽑으면 상품들을 속성 값들의 나열, 즉 벡터로 표현할 수 있게 됩니다. 예를 들면, X = [1,0,2,3,2] Y = [1,0,3,2,1] Z = [0,1,3,1,1] 이런 식인거죠. 이렇게 아이템마다 벡터화를 해주고 나면, 아이템간 유사도를 구할 수 있습니다. 어떤 아이템이 과연 어떤 아이템과 가장 비슷한가? 혹은 비슷하지 않은가?를 계산할 수 있는 것이죠. 이 포스팅에서는 벡터를 이용하여 계산할 수 있는 유사도들을 알아보겠습니다. 1. 자카드 유사도(Jaccard Similarity) 자카드 유사도는 집합의 개념을 이용하는데요, 한..

데이터를 파악하기 위해서는 시각화가 필수입니다. 데이터가 어떻게 생겼는지 확인하기 위해 여러 그림을 그리다보면 한번에 그리고 싶을 때가 있죠. 본 포스팅에서는 matplotlib의 subplots 함수와 seaborn 라이브러리를 이용하여 그래프를 한번에 여러개 그려보도록 하겠습니다. 먼저 필요한 라이브러리들과 데이터를 불러옵니다. 데이터는 캐글에서 가져온 HR 자료를 사용했습니다. import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt df = pd.read_csv('./data/HR_comma_sep.csv') display(df.shape, df.head()) 위 데이터로부터 부서(Depa..
데이터 분석을 할 때 빠지면 섭섭한 자료형이 바로 날짜, 시간입니다. 고객이 행동을 하면 기록되는 웹페이지 로그라던가 초단위로 집계되는 기계의 자동화 시스템이 시간과 함께 저장되는 대표적인 데이터라고 할 수 있겠습니다. 시간, 시점과 관련한 분석을 실행하기 위해서는 파이썬에서 어떻게 날짜와 시간을 처리하는지 알아야겠죠. 본 포스팅에서는 파이썬에서 날짜와 시간을 다루는데 사용되는 datetime 라이브러리 사용방법에 대해 알아보겠습니다. datetime 라이브러리 소개 datetime은 파이썬에서 날짜와 시간을 다루는 클래스, 함수들을 모아놓은 라이브러리입니다. datetime 라이브러리는 날짜와 시간을 함께 저장하는 datetime 클래스, 날짜 정보를 저장하는 date 클래스, 시간 정보를 저장하는 t..

JSON 파일이란? JSON은 JavaScript Object Notation의 약자로 JavaScript 언어의 자료형을 텍스트로 표현한 포맷입니다. 키-값 쌍으로 이루어져 있으며 사람이 쉽게 읽을 수 있도록 구성되어 있습니다. 서로 다른 시스템간에 데이터를 교환하기에 좋고, 언어가 다르더라도 데이터를 교환하는데 용이하다는 장점이 있습니다. JSON은 데이터를 키(key)와 값(value)로 표현하고, 이를 중괄호 {}로 감싸서 표현합니다. 예를 들면 {"점수" : 80} 이런 식이죠. 키는 큰따옴표로 묶은 문자열이고, 여러 개의 키-값 쌍을 저장하고 싶다면 쉼표(, comma)로 구분합니다. 만약 값으로 둘 이상의 값들을 사용하고 싶다면 대괄호 []로 묶어주면 됩니다. ex) {"singer": "T..