문제 설명 두 개의 단어 begin, target과 단어의 집합 words가 있습니다. 아래와 같은 규칙을 이용하여 begin에서 target으로 변환하는 가장 짧은 변환 과정을 찾으려고 합니다. 한 번에 한 개의 알파벳만 바꿀 수 있습니다. words에 있는 단어로만 변환할 수 있습니다. 예를 들어 begin이hit, target가cog, words가 [hot, dot, dog, lot, log, cog]라면hit->hot->dot->dog->cog와 같이 4단계를 거쳐 변환할 수 있습니다. 두 개의 단어 begin, target과 단어의 집합 words가 매개변수로 주어질 때, 최소 몇 단계의 과정을 거쳐 begin을 target으로 변환할 수 있는지 return 하도록 solution 함수를 작성해..

Pandas 기초 마지막 포스팅입니다. 여기서는 데이터를 요약하는 몇가지 함수들을 알아보겠습니다. describe() : 수치형 칼럼 요약 grades.describe().round(2) describe()는 수치형 값을 갖는 칼럼에 한해 count(빈도수), mean(평균), std(표준편차), min(최솟값), 25%(제1사분위수), 50%(제2사분위수), 75%(제3사분위수), max(최댓값)를 제공합니다. round(N)는 소수점 자리수에서 반올림을 해주는 함수인데, N+1번째 자릿수에서 반올림하여 소숫점 아래 숫자를 N개만 남깁니다. quantile() : 분위수 구하기 grades.quantile([0.1, 0.4, 0.7, 0.9]) 사용자가 직접 구하고 싶은 분위수를 지정하여 값을 얻을 수..
지난 포스팅()에서는 Pandas 라이브러리를 활용하여 데이터프레임 만들기, 조회하기를 알아보았습니다. 이번 포스팅에서는 만들어진 데이터프레임을 활용하여 칼럼명 변경, 정렬, 결합 그리고 칼럼 순서 변경에 대해 알아보겠습니다. rename : 칼럼명 변경 특정 칼럼의 이름을 변경하기 위해 rename()을 사용합니다. 여기서는 Math 칼럼의 이름을 MATH로 변경하였습니다. print(grades.columns) grades.rename(columns = {'Math':'MATH'}, inplace = True) print(grades.columns) Index(['Math', 'Science', 'English', 'History'], dtype='object') Index(['MATH', 'Scie..
pandas_tutorial-1 Pandas tutorial 1 - 데이터 만들기부터 조회까지¶ tidy data란¶데이터 분석을 위해선 정돈된 형태의 데이터를 구축해 놓는 것이 필수적이죠. 타이디(tidy, 깔끔한) 데이터는 작업하기 매우 용이한, 정형화된 형태의 데이터로, 다음을 만족해야 합니다. 각 관측값마다 해당되는 행이 있어야하고, 각 변수마다 해당되는 열이 있어야하고, 값마다 해당하는 하나의 셀이 있어야 합니다. 일반적으로 엑셀에 데이터를 입력하는 방식과 동일하다고 생각하시면 됩니다. 예를 들어, 어떤 학급에서 학생들이 시험을 치루었고, 그 성적을 입력한다고 합시다. 각 열은 해당 학급에 속하는 학생의 번호, 이름, 국어점수, 수학점수, 영어점수를 의미하고, 각 행은 한명의 학생에 대한 관측값..
Numpy는 과학 계산을 위해 반드시 필요한 패키지입니다. 다차원 배열을 위한 기능과 선형 대수 연산, 수학 함수, 유사 난수 생성기를 포함합니다. 핵심 기능은 다차원 배열인 ndarray 클래스로, 이 배열의 모든 원소는 동일한 데이터 타입이어야 합니다. 1. 배열 만들기 numpy 배열은 리스트로 구현합니다. import numpy as np a = np.array([1, 2, 3]) b = np.array([[1.5, 2, 3], [4, 5, 6]]) print(a) print(b) [1 2 3] [[1.5 2. 3. ] [4. 5. 6. ]] np.zeros([행의 수, 열의 수]) np.zeros([3, 4]) # 영행렬 생성 array([[0., 0., 0., 0.], [0., 0., 0., ..

R에서 원소에 동일한 연산을 반복적으로 수행하고 싶을 때 apply 계열의 함수를 사용합니다. 일반적으로 반복 계산을 할 때 사용하는 for, while보다 시간이 적게 듭니다. 1. apply() 행렬이나 데이터 프레임의 행, 열에 대해 함수를 적용할 때 사용합니다. apply(x, margin, function) margin = 1 : 행에 대한 연산 margin = 2 : 열에 대한 연산 margin = c(1,2) : 원소에 대한 연산 2. lapply() 리스트에 적용하며 결과 역시 리스트로 반환합니다. lapply(x, function) 3. sapply() lapply()와 유사한데요, lapply()는 결과를 리스트로 반환하는 반면 sapply()는 결과를 벡터나 행렬로 반환합니다. 4. ..
1. Lv 1 - 예산(소팅) def solution(d, budget): total = 0 cnt = 0 d = sorted(d) for request in d: total += request if total >> list(zip([1, 2, 3], [4, 5, 6])) [(1, 4), (2, 5), (3, 6)] 4. Lv 2 - 가장 큰 수 from functools import cmp_to_key def solution(numbers): numbers = list(map(str, numbers)) func = lambda x, y: int(x + y) - int(y + x) numbers = sorted(numbers, key = cmp_to_key(func), reverse = True) ans..

문제 설명 스파이들은 매일 다른 옷을 조합하여 입어 자신을 위장합니다. 예를 들어 스파이가 가진 옷이 아래와 같고 오늘 스파이가 동그란 안경, 긴 코트, 파란색 티셔츠를 입었다면 다음날은 청바지를 추가로 입거나 동그란 안경 대신 검정 선글라스를 착용하거나 해야 합니다. 종류 이름 얼굴 동그란 안경, 검정 선글라스 상의 파란색 티셔츠 하의 청바지 겉옷 긴 코트 스파이가 가진 의상들이 담긴 2차원 배열 clothes가 주어질 때 서로 다른 옷의 조합의 수를 return 하도록 solution 함수를 작성해주세요. 제한 사항 clothes의 각 행은 [의상의 이름, 의상의 종류]로 이루어져 있습니다. 스파이가 가진 의상의 수는 1개 이상 30개 이하입니다. 같은 이름을 가진 의상은 존재하지 않습니다. clot..
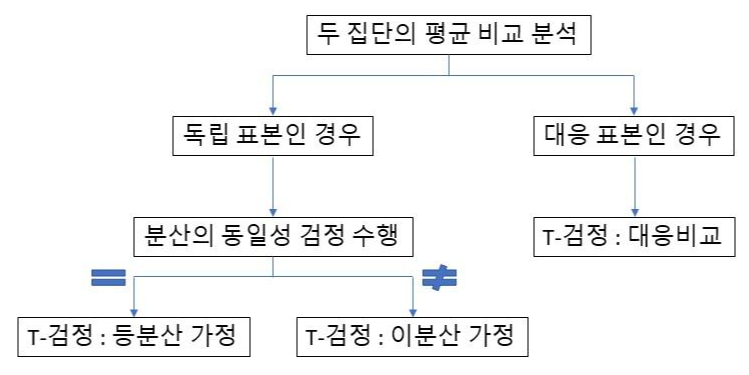
락 음악과 클래식 음악으로 분류되는 노래들의 길이는 유의미하게 차이가 날까요? 유산소 운동과 무산소 운동을 할 때 소비되는 칼로리에 차이가 있을까요? 이렇게 두 집단(락/클래식, 유산소/무산소)에 따라 값(노래 길이, 소비된 칼로리)의 평균에 차이가 존재하는지를 알아보고자 할 때, T-검정(T-test)을 사용합니다. 여기서 독립변수는 두 집단을 갖는 범주형 변수, 종속변수는 연속형 변수여야 합니다. 두 집단 평균 비교시 절차 독립 표본인 경우 독립적으로 추출된 두 집단의 모평균의 차이를 검정하기 위해 가설은 다음과 같이 설정합니다. $$H_0 : \mu_1 = \mu_2, \quad H_1 : \mu_1 \ne \mu_2$$ 주의해야 할 점은 두 그룹이 동등한(유사한) 집단이라는 보장이 있어야 한다는 ..
탐색 1. Lv1 - 세 소수의 합 def solution(n): num = set(range(2, n + 1)) for i in range(2, n + 1): if i in num: num -= set(range(2 * i, n + 1, i)) num = list(num) answer = 0 for i in range(len(num)): for j in range(i + 1, len(num)): if (n - num[i] - num[j]) in num[j + 1:]: answer += 1 return answer 에라토스테네스의 체 : 시간복잡도는 O(NloglogN), N = 입력으로 주어진 n 소수 구하기 : 시간복잡도는 O(M**3), M = 소수의 개수 num 대신 prime_numbers, p..