들어가며
지난 포스트에서 모델 드리프트의 개념과 원인에 대해 알아보았습니다. 시간이 지나면서 모델의 성능이 감소하는 현상을 모델 드리프트라고 하며, 모델 드리프트가 발생하는 주된 이유는 데이터의 분포가 변하기 때문이었습니다. 데이터의 분포가 변한다는 것은 구체적으로, 현재 유입되는 데이터가 모델이 학습했을 때 사용했던 데이터의 양상과 달라졌다는 것을 의미합니다. 모델이 학습되었을 때 바라봤던 데이터와 패턴이 달라지게되면 기대했던 결과와 다른 결과를 낳게 되고, 이는 모델의 성능 하락으로 이어질 수 있습니다. 때문에 모델의 안정적인 운영을 위해서 유입되는 데이터의 분포를 살펴보는 일은 중요합니다.
본 포스트에서는 어떻게 데이터의 분포 변화를 살펴볼 수 있는지 그 방법론에 대해 알아보겠습니다. 데이터는 크게 연속형인 경우와 범주형인 경우로 나눌 수 있는데, 여기서는 연속형 변수의 분포 변화를 검증하는 방법으로 KS 검정과 PSI(에 대해 다루겠습니다.
KS 검정
개념
Kolmogorov-Smirnov Test(이하 KS 검정)은 분포 비교, 가설 검정, 적합도 분석 등 다양하게 사용될 수 있는 방법론입니다. 분포 비교 시에는 하나의 데이터가 정규 분포나 균일 분포처럼 특정한 분포를 따르는지 검정하기 위해 사용할 수도 있습니다. 본 포스트에서는 데이터 드리프트를 위한 KS 검정을 다루기 위해 두 개 데이터의 분포를 비교하는 방법으로 기술하겠습니다.
KS 검정을 위해 계산하는 KS 통계량은 두 데이터의 누적 분포 함수(Cumulative Distribution Function)간 차이의 최댓값으로 정의합니다. 두 개의 누적 분포 함수가 달라서 차이가 커지면 두 데이터가 동일하다는 가설을 기각하게 되는 것이죠.
코드
파이썬에서 KS 검정을 수행하기 위해서는 scipy의 ks_2samp 함수를 사용합니다. 정규분포를 이용해 임의의 데이터를 생성하여 함수를 적용해겠습니다.
import pandas as pd
import numpy as np
import seaborn as sns
from scipy.stats import ks_2samp
np.random.seed(1234)
cls = ['before' for _ in range(50)] + ['after' for _ in range(50)]
values = np.random.normal(loc=0, scale=1, size=len(cls))
df1 = pd.DataFrame({'class': cls, 'value': values})
display(df1)
그림을 그려서 before과 after 데이터가 어떻게 다른지 확인해 보겠습니다. seaborn의 displot을 이용하여 pdf와 cdf를 그려보겠습니다.
sns.displot(data=df1, x='value', hue='class', kind='kde')
sns.displot(data=df1, x='value', hue='class', kind='ecdf')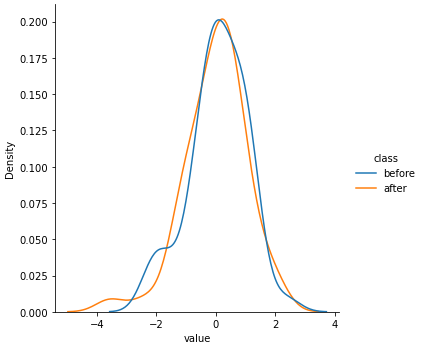
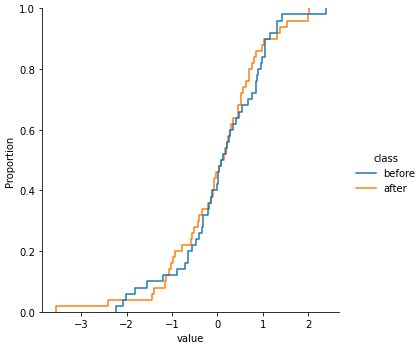
정규분포를 이용해 랜덤하게 데이터를 만들어 before 그룹과 after 그룹에 큰 차이는 없어 보입니다. 이제 KS 검정을 수행해보겠습니다.
statistic, p_value = ks_2samp(
df1.loc[df1['class'] == 'before', 'value'], df1.loc[df1['class'] == 'after', 'value'])
print('KS statistic:', statistic)
print('p-value:', p_value)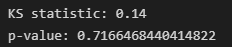
KS 통계량은 0.14, p-value는 0.7으로 계산되었습니다. p-value가 일반적으로 사용되는 유의수준인 0.05보다 커, 두 그룹의 분포가 동일하다는 가설을 기각할 수 없습니다. 따라서 두 그룹의 분포가 동일하다고 결론낼 수 있는 충분한 근거를 확보했다고 할 수 있습니다.
PSI(Population Stability Index)
개념
PSI는 Population Stability Index의 약자로, 데이터의 안정성을 평가하기 위해 많이 사용되는 지표입니다. 신용평가모형, 고객 세분화 등 다양한 분야에서 모형의 결과에 변동이 있는지 확인하기 위해 쓰이고 있습니다.
PSI는 0이상의 값을 가집니다. PSI 값이 0이면 완벽한 두 분포가 동일하다는 것을 나타냅니다. 현재 집단에서 데이터의 분포가 이전 집단과 동일하다는 것을 의미합니다. PSI 값이 증가할수록 두 집단 간의 차이 또는 불안정성이 더 커진다고 해석합니다.

PSI는 연속형인 결과를 구간화하여 구간마다의 구성비를 비교합니다. 연속형 변수, 범주형 변수 모두의 드리프트 변화 탐지에 사용할 수 있습니다.
코드
위에서 사용한 데이터와 아래 함수를 이용해 PSI를 계산해보겠습니다.
def calculate_psi(expected, actual, buckettype='bins', buckets=10, axis=0):
def psi(expected_array, actual_array, buckets):
def scale_range (input, min, max):
input += -(np.min(input))
input /= np.max(input) / (max - min)
input += min
return input
breakpoints = np.arange(0, buckets + 1) / (buckets) * 100
if buckettype == 'bins':
breakpoints = scale_range(breakpoints, np.min(expected_array), np.max(expected_array))
elif buckettype == 'quantiles':
breakpoints = np.stack([np.percentile(expected_array, b) for b in breakpoints])
expected_percents = np.histogram(expected_array, breakpoints)[0] / len(expected_array)
actual_percents = np.histogram(actual_array, breakpoints)[0] / len(actual_array)
def sub_psi(e_perc, a_perc):
'''Calculate the actual PSI value from comparing the values.
Update the actual value to a very small number if equal to zero
'''
if a_perc == 0:
a_perc = 0.0001
if e_perc == 0:
e_perc = 0.0001
value = (e_perc - a_perc) * np.log(e_perc / a_perc)
return(value)
subsum = [sub_psi(expected_percents[i], actual_percents[i]) for i in range(0, len(expected_percents))]
psi_value = sum(subsum)
return(psi_value)
if len(expected.shape) == 1:
psi_values = np.empty(len(expected.shape))
else:
psi_values = np.empty(expected.shape[axis])
for i in range(0, len(psi_values)):
if len(psi_values) == 1:
psi_values = psi(expected, actual, buckets)
elif axis == 0:
psi_values[i] = psi(expected[:,i], actual[:,i], buckets)
elif axis == 1:
psi_values[i] = psi(expected[i,:], actual[i,:], buckets)
return(psi_values)calculate_psi(
expected=df1.loc[df1['class']=='before', 'value'],
actual=df1.loc[df1['class']=='after', 'value'],
buckets=5)
일반적으로 PSI 값이 0.1 미만이면 분포 변화 없음, 0.1 이상 0.2 미만이면 약간의 분포 변화 있음, 0.2 이상이면 유의미한 분포 변화가 있다고 해석합니다. 위 결과는 약간의 분포 변화가 있다고 할 수 있겠네요.
위 기준은 널리 쓰이는 기준이긴 하지만, 도메인과 기존 데이터의 분포에 따라 분석가가 적절하게 기준값을 변경하여 사용할 수도 있습니다. 또한 연속형인 변수를 구간화하기 때문에 구간을 몇 개로 나눌 것인지 분석가가 판단하여 적용해야 합니다.
위 예제의 경우 구간의 개수(buckets)를 디폴트인 10개로 했더니 결과가 0.86으로 나왔습니다. 구간 개수를 5개로 줄였더니 PSI 값이 줄었고요. 구간 개수를 줄이면 분포 변화 탐지를 잘 못할 수 있고, 너무 많이 하면 PSI 값이 민감하게 바뀔 수 있으니 적절한 구간 개수를 선택하는 것이 중요합니다.
마치며
본 포스트에서는 데이터 드리프트를 탐지하는 방법인 KS 검정과 PSI 를 알아보았습니다. 두 개 방법론 모두 특별한 가정을 필요로 하지 않는 비모수적 방법으로, 어떤 상황에서든 쉽게 적용할 수 있습니다.
드리프트를 확인하려는 데이터를 잘 이해하고, 분포를 살펴보고 어떤 방법론이 적절할지 결정하시길 바랍니다. 데이터가 정규 분포 형태인지, 치우친 형태인지에 따라 방법론마다 결과가 다를 수 있기 때문이죠.
KS 검정과 PSI 외에도 데이터의 분포 차이를 판단하는 방법론은 다양하게 있으니 구글이나 챗지피티의 도움을 받아 더 깊게 알아보는 것도 추천합니다. 궁금한 점이나 잘못 쓰인 점이 있다면 댓글로 알려주세요. 읽어주셔서 감사합니다 😁
참고
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ks_2samp.html#scipy.stats.ks_2samp
scipy.stats.ks_2samp — SciPy v1.10.1 Manual
[1] Hodges, J.L. Jr., “The Significance Probability of the Smirnov Two-Sample Test,” Arkiv fiur Matematik, 3, No. 43 (1958), 469-86.
docs.scipy.org
https://www.analyticsvidhya.com/blog/2021/10/mlops-and-the-importance-of-data-drift-detection/
The Importance of Data Drift Detection that Data Scientists Do Not Know
There are various ways to detect and handle data drift. Let us have a look at various methods using which we can detect data drift
www.analyticsvidhya.com
https://www.credit.co.kr/ib20/mnu/BZWCACCCS15
NICE지키미
1위 신용평가기관, 신용점수 올라가는 나이스한 신용습관
www.credit.co.kr
https://github.com/mwburke/population-stability-index
GitHub - mwburke/population-stability-index: Python implementation of the population stability index (PSI)
Python implementation of the population stability index (PSI) - GitHub - mwburke/population-stability-index: Python implementation of the population stability index (PSI)
github.com
'繩鋸木斷水滴石穿 > AI | 머신러닝' 카테고리의 다른 글
| [Tips] 범주형 변수의 카테고리 개수를 줄이는 방법들 (2) | 2023.09.10 |
|---|---|
| [sklearn] LabelEncoder와 OrdinalEncoder 비교 (0) | 2023.08.27 |
| [모니터링] 1) model drift의 개념과 원인(data drift, label drift, concept drift) (0) | 2023.04.16 |
| [metric] 군집분석 평가 지표 1: 실루엣 계수(Silhouette Coefficient) (1) | 2023.03.24 |
| [annoy] annoy 사용방법: 추천시스템에서 유사 아이템 찾기 (1) | 2022.11.13 |