군집분석과 실루엣 계수
군집분석(Clustering)은 범주형 타겟에 대한 사전 정보가 없는 경우, 전체를 몇 개 군집으로 그룹화하여 각 군집의 특징을 파악하는 분석 방법론입니다. 그룹화를 수행할 때는 주어진 관측값들 사이의 거리 또는 유사성을 이용합니다. 동일한 군집에 속하는 데이터는 특징이 서로 비슷하고, 서로 다른 군집에 속한 데이터는 그렇지 않도록 구성해야 합니다. 군집분석에 사용되는 대표적인 알고리즘으로는 KMeans, DBSCAN이 있습니다.
일반적인 회귀나 분류 문제의 경우 타겟이 명확하게 존재하는 비지도 학습으로, 모델의 결과와 그 타겟을 비교하여 모델의 성능을 평가할 수 있습니다. 하지만 군집분석의 경우 비지도 학습으로, 비교할 수 있는 타겟이 존재하지 않습니다.
다행히 군집화가 효율적으로 잘 됐는지를 평가할 수 있는 지표들이 아예 없지는 않습니다. 비지도 학습의 특성상 정확하고 절대적인 성능 평가는 어렵지만, 실루엣 계수라는 방법을 이용할 수 있습니다. 본 포스트에서는 예시 데이터를 사용하여 kmeans를 적용해 군집화를 수행하고, 실루엣 계수를 구하는 절차를 코드와 함께 소개드리겠습니다.
예시 데이터
먼저 필요한 라이브러리들을 불러오겠습니다.
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.metrics import silhouette_score
%matplotlib inline
사이킷런은 군집화 알고리즘을 테스트해 보기 위한 데이터 생성기를 제공합니다. 대표적인 군집화용 데이터 생성기인 make_blobs()를 사용하여 데이터를 생성해보겠습니다. 사용하는 파라미터는 아래와 같습니다.
- n_samples: 생성할 데이터의 총 개수
- n_features: 데이터의 특성 개수
- centers: (int) 군집의 개수, (ndarray) 개별 군집 중심점의 좌표
- cluster_std: (float) 생성될 군집 데이터의 표준 편차, (ndarray) 군집별로 서로 다른 표준 편차를 가지는 경우 각 군집의 표준 편차
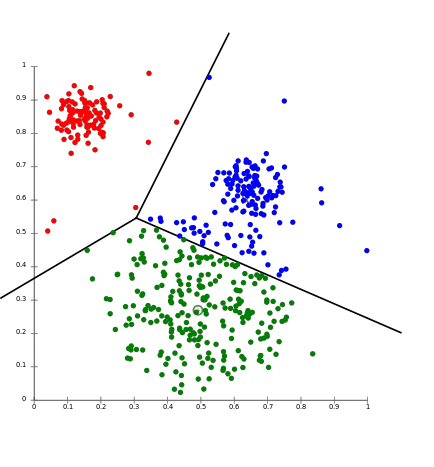
아래는 200개의 데이터와 2개의 특성, 3개의 군집을 가진 데이터세트를 만드는 코드입니다. 군집 분석을 위한 데이터셋의 경우 대체로 실제 타겟이 존재하지 않지만, 여기서는 성능지표 비교를 위해 타겟을 사용한 점 참고하시면 좋겠습니다!
X, y = make_blobs(n_samples=200, n_features=2, centers=3, cluster_std=0.9, random_state=0)
unique, counts = np.unique(y, return_counts=True)
print(X.shape, y.shape)
print(unique, counts)(200, 2) (200,)
[0 1 2] [67 67 66]
보기 좋게 데이터를 확인하기 위해 데이터프레임 형식으로 맞춰보고 시각화도 해봤습니다.
df = pd.DataFrame(data=X, columns=['ftr1', 'ftr2'])
df['target'] = y
df.head()
target_list = np.unique(y)
markers = ['o', 's', '^', 'P']
for target in target_list:
target_cluster = df[df['target'] == target]
plt.scatter(x=target_cluster['ftr1'], y=target_cluster['ftr2'], edgecolor='k', marker=markers[target])
plt.show()
실루엣 계수(silhouette coefficient)
정의
실루엣 계수는 개별 데이터가 할당된 군집 내 데이터와 얼마나 가깝게 군집화 되어있는지, 그리고 다른 군집에 있는 데이터와는 얼마나 멀리 분리되어 있는지를 수치로 나타냅니다. 군집이 잘 분리되었다는 것은 동일한 군집 내에서의 데이터는 서로 가깝게 위치해있으며 다른 군집과의 거리는 멀음을 의미합니다. 값이 크다면 군집화의 성능이 좋다고 해석할 수 있습니다.
실루엣 계수는 아래와 같은 식에 의해 계산됩니다.
$ s(i) = \frac{b(i) - a(i)}{max(a(i), b(i))}, \quad i=개별 데이터 인덱스 $
a(i)는 개별 데이터의 동일한 군집 내 다른 데이터들과의 평균거리이며, b(i)는 가장 가까운 군집과의 평균 거리를 의미합니다.
실루엣 계수는 -1에서 1 사이의 값을 가지며 1에 가까울 수록 근처 군집과 멀리 떨어져 있음을, 0에 가까울수록 근처 군집과 가까움을 의미합니다. -(마이너스)이면 아예 다른 군집에 데이터가 할당됐음을 의미합니다.
각 데이터에 대해 실루엣 계수를 구한 후 평균을 내면 전체 데이터의 실루엣 스코어를 구할 수 있습니다. 일반적으로 이 값이 크면(1에 가까우면) 군집화가 어느정도 잘 되었다고 판단하는데요, 단순히 값이 크다고 해서 군집화가 잘 됐다고 판단할 수는 없습니다.
전체 실루엣 스코어와 더불어 개별 군집의 평균값의 편차가 크지 않은 경우에만 전체 군집화 성능이 좋다고 판단할 가능성이 생깁니다. 개별 군집의 실루엣 스코어가 전체 실루엣 스코어와 크게 다르지 않아야 된다는 뜻입니다. 전체 실루엣 스코어가 클지라도 개별 군집의 실루엣 스코어가 들쭉날쭉하다면 군집화가 잘되었다고 할 수 없다는 의미이죠.
군집마다의 실루엣 스코어를 구해보고, 시각화도 해보는 등 여러 검정을 거쳐야 군집화의 성능을 정확하게 판단할 수 있습니다.
장단점
실루엣 계수는 식이 단순하고 직관적이어서 이해하기에 쉽습니다. 군집 개수를 다르게 하여 각 값을 비교함으로써 최적의 군집 개수를 정하는 데에 사용될 수도 있고요.
단, 밀도 기반 클러스터링 알고리즘(밀도가 높은 부분을 클러스터링하는 방식으로, 대표적인 밀도 기반 알고리즘으로 DBSCAN가 있음)에 한해 값이 크게 산출되는 경향이 있기 때문에 유의하고 사용해야 합니다. 밀도 기반이 아닌 중심 기반 알고리즘을 사용해 클러스터링을 한 후 비교하게 되면, 밀도 기반 알고리즘이 유리하게 나타날 가능성이 높다는 의미입니다.
또한 데이터마다 다른 데이터와의 거리를 반복적으로 계산해야 되기 때문에 데이터가 많으면 계산량이 급격히 늘어난다는 문제점도 있습니다. 이런 경우에는 군집별로 데이터를 샘플링하여 평가하는 방안을 모색해야 되겠습니다.
파이썬 코드 적용하기
대표적인 군집화 알고리즘인 KMeans를 사용하여 군집화를 수행하고, scikit-learn에서 제공하는 실루엣 함수를 적용하여 성능을 측정해보겠습니다. 알고리즘에서 사용할 파라미터는 아래와 같습니다.
n_clusters: 군집 개수
init: 초기에 군집 중심점의 좌표를 설정하는 방식
max_iter: 최대 반복횟수, 이 횟수 이전에 모든 데이터의 중심점 이동이 없으면 종료함
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=200, random_state=0)
cluster_labels = kmeans.fit_predict(X)
df['kmeans_label'] = cluster_labels
df.head()
사이킷런이 제공하는 silhouette_samples 함수를 사용하면 각 데이터마다 실루엣 계수를 얻을 수 있습니다. X는 사용할 특성들이며 labels는 군집 레벨을 정해줍니다. 실제 타겟과 kmeans로 예측한 라벨 각각에 대해 실루엣 계수를 구해보았습니다.
df['real_silhouette'] = silhouette_samples(X=df[['ftr1', 'ftr2']], labels=df['target'])
df['pred_silhouette'] = silhouette_samples(X=df[['ftr1', 'ftr2']], labels=df['kmeans_label'])
df.head()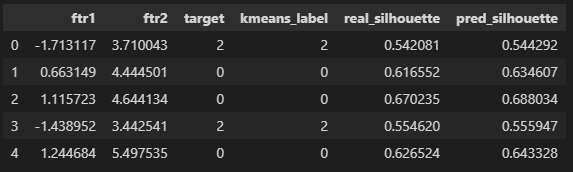
전체 실루엣 스코어는 silhouette_score 함수를 이용하여 계산할 수 있습니다. 계산 결과, 실제 타겟의 실루엣 스코어보다 kmeans로 예측한 군집의 실루엣 스코어가 조금 더 컸음을 알 수 있었습니다.
real_ss = silhouette_score(X=df[['ftr1', 'ftr2']], labels=df['target'])
pred_ss = silhouette_score(X=df[['ftr1', 'ftr2']], labels=df['kmeans_label'])
print(f'실제 silhouette score: {real_ss: .4f}')
print(f'예측 silhouette score: {pred_ss: .4f}')실제 silhouette score: 0.5258
예측 silhouette score: 0.5341
위에서 군집이 잘 되었다면, 전체 실루엣 스코어와 더불어 개별 군집의 평균값의 편차가 크지 않아야 한다고 했었는데요. 군집별 실루엣의 평균을 확인해보니, kmeans로 예측한 군집들의 편차가 더 작음을 알 수 있었습니다. 전체 실루엣 스코어도 kmeans의 경우가 조금 더 컸기 때문에, 향후에 결과를 활용한다면 실제 타겟보다 kmeans를 사용할 가능성도 남겨둘 수 있겠죠.
display(df.groupby('target')['real_silhouette'].mean())target
0 0.479505
1 0.585387
2 0.512267
Name: real_silhouette, dtype: float64
display(df.groupby('kmeans_label')['pred_silhouette'].mean())kmeans_label
0 0.518746
1 0.569303
2 0.512431
Name: pred_silhouette, dtype: float64
시각화
각 군집별로 개별 데이터의 실루엣 계수와 전체 실루엣 스코어를 보기 쉽게 확인하기 위하여 matplotlib 라이브러리를 사용해 시각화를 해보겠습니다. 파이썬 머신러닝 완벽가이드 깃허브에 있는 코드를 사용하였습니다. 아래는 KMeans 알고리즘을 사용하여 군집을 2, 3, 4개씩 만들고 각 군집별 실루엣 계수를 시각화한 결과입니다.
visualize_silhouette([2, 3, 4], X)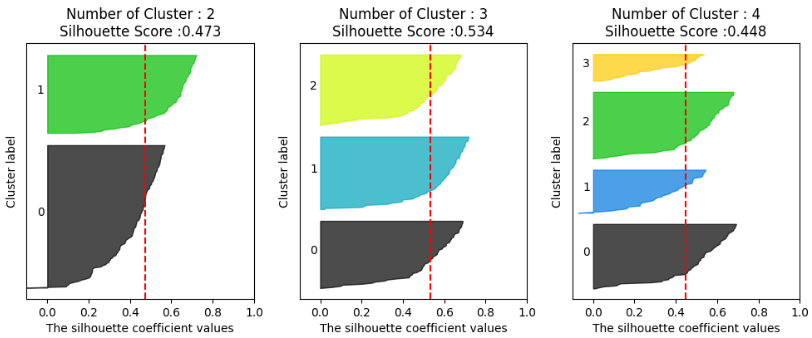
빨간선은 전체 실루엣 계수의 평균으로, 이 값과 각 그룹의 평균 실루엣 계수가 유사해야 군집화가 잘 되었다고 판단할 수 있습니다. 위 그래프를 보면 군집이 3개일 때 실루엣 계수가 가장 높으므로 적합한 군집의 개수로 3을 채택할 수 있겠습니다.
마치며
지금까지 군집분석의 정의, 군집분석을 평가하는 지표인 실루엣 계수 그리고 파이썬을 이용한 구현 방법에 대해 알아보았습니다. 군집분석은 비즈니스에서 고객 세그멘테이션과 같은 과제에 사용될 수 있는데요. 실루엣 계수와 같은 성능지표를 이용하여 알고리즘을 평가하고 강조할 수도 있겠습니다만, 비즈니스에서 더욱 중요한 것은 그 군집의 결과를 갖고 어떻게 활용할 것인지, KPI를 어떻게 얻어낼 것인지임을 놓치지 않으면 좋겠습니다.
관련하여 잘못된 점이나 궁금한 점이 있으시면 편하게 댓글 주세요. 감사합니다 😁
참고
파이썬 머신러닝 완벽 가이드 - YES24
『파이썬 머신러닝 완벽 가이드』는 이론 위주의 머신러닝 책에서 탈피해 다양한 실전 예제를 직접 구현해 보면서 머신러닝을 체득할 수 있도록 만들었다. 캐글과 UCI 머신러닝 리포지토리에서
www.yes24.com
sklearn.metrics.silhouette_score
Examples using sklearn.metrics.silhouette_score: A demo of K-Means clustering on the handwritten digits data A demo of K-Means clustering on the handwritten digits data Demo of DBSCAN clustering al...
scikit-learn.org
GitHub - wikibook/ml-definitive-guide: 《파이썬 머신러닝 완벽 가이드》 예제 코드
《파이썬 머신러닝 완벽 가이드》 예제 코드. Contribute to wikibook/ml-definitive-guide development by creating an account on GitHub.
github.com
https://towardsdatascience.com/7-evaluation-metrics-for-clustering-algorithms-bdc537ff54d2
7 Evaluation Metrics for Clustering Algorithms
In-depth explanation with Python examples of unsupervised learning evaluation metrics
towardsdatascience.com
http://bigdata.dongguk.ac.kr/lectures/datascience/_book/%EA%B5%B0%EC%A7%91%EB%B6%84%EC%84%9D.html
14 장 군집분석 | 데이터과학
\(P\)를 실제로 속한 그룹(클래스)에 따라 데이터를 나눈 파티션이라고 하고, \(Q\)를 클러스터링 알고리즘의 결과 그룹에 의한 파티션이라고 하자. 즉, \(P = \{P_1, P_2, ..., P_S\}\), \(Q = \{Q_1, Q_2, ..., Q_K
bigdata.dongguk.ac.kr
'繩鋸木斷水滴石穿 > AI | 머신러닝' 카테고리의 다른 글
| [모니터링] 2) 드리프트 감지 방법: KS 검정과 PSI (2) | 2023.05.28 |
|---|---|
| [모니터링] 1) model drift의 개념과 원인(data drift, label drift, concept drift) (0) | 2023.04.16 |
| [annoy] annoy 사용방법: 추천시스템에서 유사 아이템 찾기 (1) | 2022.11.13 |
| RFE와 REFCV: 유의미한 변수를 선택하는 방법 (1) | 2022.07.17 |
| [AutoML] pycaret 패키지를 이용한 분류모델 학습 (2) create_model, tune_model, predict_model, finalize_model (1) | 2022.04.24 |