서울우먼잇츠 팀트랙 스터디에 참여 중이다. 바이브코딩이 메인 주제인 스터디인데, 처음 한 달은 구글클라우드스킬부스트를 통해 스킬 뱃지를 획득했고 이후 한 달은 바이브코딩을 적용해 실제 서비스를 구축해보기로 했다. 이전에는 마라톤 계획 세우기 웹서비스를 배포했었다.(후기는 여기)
이번에는 대시보드 구현을 위해 바이브코딩을 활용해보기로 했다. 바이브코딩으로 사용할 도구는 codex이고, 대시보드의 대상은 vllm metrics이다. vllm은 언어모델 서빙 지표를 metrics 엔드포인트로 제공하고 있는데, 이를 prometheus에서 스크래핑하고 grafana에서 시각화할 수 있다. 어차피 업무로 해야할 일이고, 대시보드를 커스텀하는 작업을 바이브코딩으로 풀어볼수 있지 않을까 싶어 진행해보기로 했다.
Codex 사용해보기
claude code가 MCP 등장과 함께 굉장한 인기를 끌고 있다지만, 8~9월쯤 갑자기 성능이 떨어지는 등 오류가 잦았다고 한다. 이때 사람들이 갈아탄 다른 도구 중 하나가 바로 OpenAI의 Codex이다. 나야 Plus 플랜을 구독 중이기도 하니, 사용하지 않을 이유는 특별히 없었다. 또한 이번에 작업할 내용은 복잡한 서비스를 만드는 것이 아니라, 이미 잘 되어있는 것에서 커스텀을 조금 해보려는 것 뿐이어서 가볍게 시작해볼 법 하다고 생각했다.
GPT5가 출시되면서 내부적으로 쿼리를 분석해 Reasoning Effort 단계를 나눈다던데, codex도 마찬가지로 이 단계를 사용자가 선택할 수 있다. 기획을 하고 요구사항을 작성할 때는 좀 생각을 많이 하게 시킨다던가, 단순한 코드 스니펫 생성 작업에는 빠르게 할 수 있는 모델을 쓴다거나 하는 식으로 적절하게 선택하면 좋을 것 같다.
소소한 단점이라고 한다면, 한국어 원어민인 내가 한국어로 질문을 작성해도 영어로 답변해주는 경향이 많다는 점이다. 똑똑한 영어 사용자 직원을 둔 것 같다. 좀 불편하긴 한데 영어 공부를 하는 셈 쳐도 좋겠다. 꿋꿋하게 계속 한국어로 질문하니까 최근엔 한국어 답변을 좀 더 제공해주는 것 같다. 지표로 증명하긴 어렵지만 느낌이 그렇다.
Prometheus와 Grafana 연동하기
prometheus와 grafana 모두 처음 사용하는 툴이었다. 도커를 설치하고 연결해야 한다는데, 설치야 그렇다 치더라도 어떤 식으로 vllm과 연결해야할 지 모호했다. 다행히 구글링으로 이 가이드를 찾았고 가이드에서 제안하는 구조 그대로 적용하면서 시작할 수 있었다.
monitoring/
├── prometheus/
│ ├── prometheus.yml
│ └── rules/
├── grafana/
│ ├── provisioning/
│ │ ├── datasources/
│ │ │ └── prometheus.yml
│ │ └── dashboards/
│ │ └── dashboard.yml
│ └── dashboards/
│ └── vllm-dashboard.json
├── docker-compose.monitoring.yml
├── monitoring.env
└── start-monitoring.sh
vllm이 내부 상태/성능 지표를 /metrics 엔드포인트로 보내면, Prometheus가 이를 주기적으로 스크랩해 시계열 데이터로 저장하고 이후에 Grafana가 그 데이터를 대시보드로 시각화하는 식으로 연결한다고 한다. vllm을 구동 중인 서버에서 바로 curl로 metrics을 확인할 수도 있지만, 완전 날 것이어서 그대로 이해하기는 어렵기 때문에 이를 정리해주는 도구들의 도움이 필요했다.
이전에는 AI를 배치로 작업하거나, API를 사용했기 때문에 대단하게 운영/모니터링에 신경쓸 일이 없었다. 문제는 지금 개발해야하는 서비스는 폐쇄망에서 소형언어모델을 이용해 실시간으로 운영해야한다는 점.. 주어진 GPU 자원이 버틸 수 있을 만한 트래픽인지, 어떤 시점에 요청이 많아지는지, 혹은 GPU가 오버되어 CPU로 넘어가고 있지는 않은지 등을 모니터링 하기 위해 위 도구들은 필수라고 생각했다. 우리가 사용할 모델은 작은 편이어서 latency가 5초 이상 걸릴 일은 없겠지만(없어야만 한다) 혹시나 요청이 밀리는 등 문제가 발생하는 상황을 추적 관찰, 분석하려면 서버 상황을 적절한 지표와 함께 모니터링하는 것은 피할 수 없었다. 이 자료를 갖고 나중에 모델을 추가로 올리거나 GPU를 추가해야 한다는 등 의사결정을 해야할 수도 있다.
대시보드 수정하기
vllm은 친절하게도 대시보드 예시를 제공하고 있다. 이 문서 제일 하단에 grafana.json이라고 하는 예시를 사용하면 된다.(위 디렉토리 구조에서 vllm-dashboard.json에 해당)
문제는 지금 모델 2개를 서빙하는 상황이었고, 각각을 대시보드에서 표현해야 했다. 많은 요청을 던졌을 때 간혹 시간이 오래 걸리는 경우가 있어서 이런 이상치를 관측할 수 있는 패널도 필요했다. vllm에서 제공하는 예시는 1500 라인에 달했고 하나하나 이해하며 수정하기엔 너무 오랜 시간이 걸릴 것이 당연했기 때문에 Codex의 힘을 빌렸다.
멀티모델 시각화가 가능할 것
당연히 위 구조를 먼저 구성하고, grafana 대시보드 예시도 적용한 후, 이 monitoring 디렉토리에서 codex를 실행하여 시작했다. 먼저 현재 예시가 하나의 vllm 서버에서 모델 하나만 모니터링하는 것이니, 두 개 모델에서도 가능하게 해달라고 했다. 불필요하게 너무 많은 파일을 수정하지 않도록 현재 디렉토리 구조와 파일의 역할을 잘 이해하고 필요한 작업만 하라는 지시도 덧붙였다.
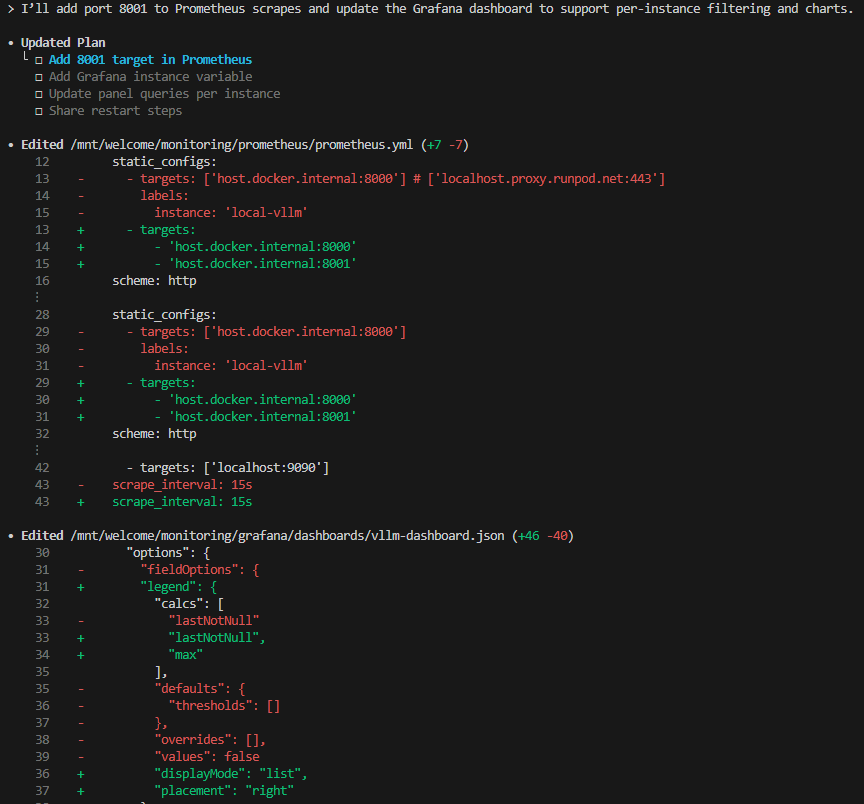
아래와 같이 prometheus.yml와 vllm-dashboard.json을 멀티모델에 맞게 수정해주었다.
이상치 탐색이 가능할 것
하나의 텍스트를 분석하기 위해 N번씩 병렬로 요청하는 테스트를 하면서 latency가 유독 길어지는 병목현상을 발견할 수 있었다. 여기서 latency는 이 모니터링을 도입하기 전, python client를 기준으로 측정한 값이다. 보통은 1초 이내에서 작업이 끝나야 하지만 결과를 얻는 데까지 3초 이상이 걸릴 때도 있어서 실제로 모델 추론 과정에서의 문제인지 확인이 필요했다. 공식 문서를 보면 이런 outlier만 특정해서 지표로 제공하고 있지는 않지만, histogram으로 제공되는 e2e_request_latency_seconds, request_queue_time_seconds와 같은 정보를 이용하면 가능할 것 같았다. 역시나 codex한테 물어보니 아래처럼 활용하여 관측할 수 있다고 제안해줬다.
histogram_quantile(0.999, sum by (le, model) (rate(vllm:e2e_request_latency_seconds_bucket{model=~\"$model\"}[$__rate_interval])))
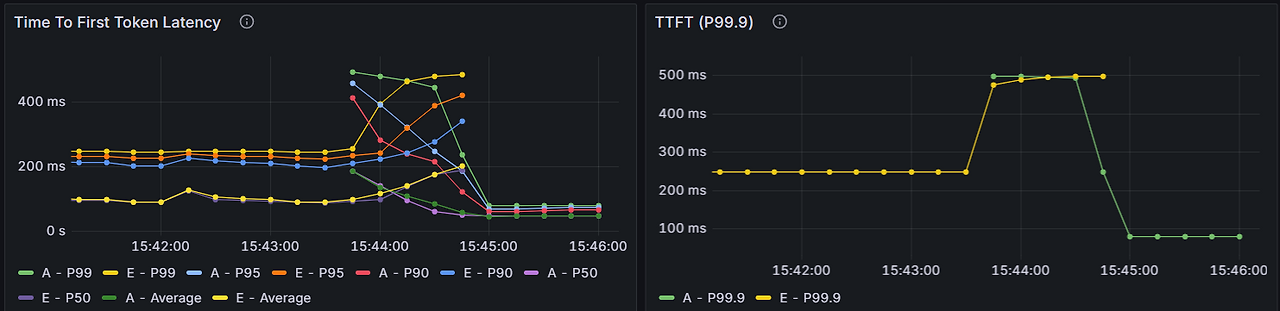
grafana로 확인한 결과는 아래와 같다.

다만 왼쪽 패널의 경우 평균, 50/90/95/99분위수 값이 두 개 모델에 대해 모두 그려지고 있어서 썩 보기 좋은 결과는 아닌 것 같다. 아쉽게도 99.9분위수까지 확인해봤지만 위에서 언급한 간혹 오래 걸리는 현상을 설명할 방법은 찾지 못했다. 대기 시간도 0.2~0.4초 수준이었는데 모델 레벨에서의 소요시간이 문제가 아니라, 클라이언트로 보내는 과정에서의 문제.. 이런 것이 아닐까? 추측한다. 아니면 조금씩 지연되는 시간들을 모으고 나니 클라이언트 입장에서는 총 4초입니다!! 이런 거일 수도 있고. 아무튼 모델 자체에 문제는 없는 것을 확인했으니 문제의 절반은 해결했다고 본다. 조만간 대형언어모델이 아니라 진짜 사람들에게 물어봐야겠다.
유사한 패널끼리 묶어 순서 조정할 것
이미 잘 짜여진 dashboard.json이지만 이상치 패널 추가하고 다른 요소들도 좀 테스트 한다고 추가하고 어쩌고 하다보니 좀 보기 불편해졌다. 해서 순서 조정하는 작업도 시켰다. 내가 1500줄이나 되는 json을 뜯어가며 순서 고치기에는 시간도 너무 오래 걸릴테고, comma 하나, 중괄호 하나 잘못 지웠다가는 꼬일 확률이 충분했다. 대충 보고 id key가 순서인가 싶었는데, 순서대로 있지도 않으니 그건 아닌 거 같았다. codex에게 유사한 패널들끼리 잘 묶어서 정렬해달라고 하니, gridPos 의 x, y 값만 조정해 위치를 잘 조정해주었다. 덕분에 최종적으로 아래와 같은 대시보드들을 얻을 수 있었다.

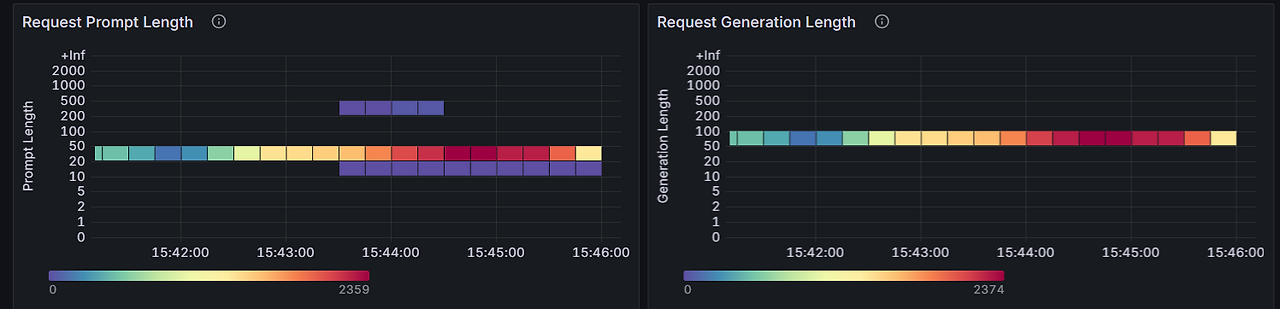
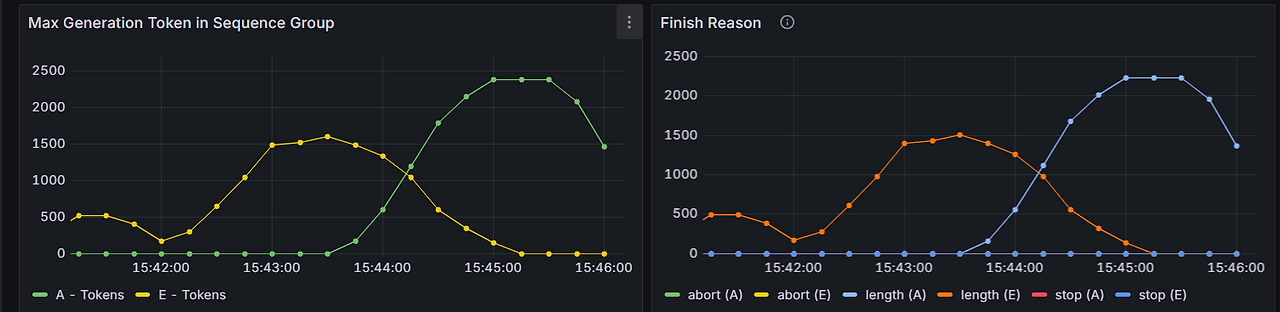

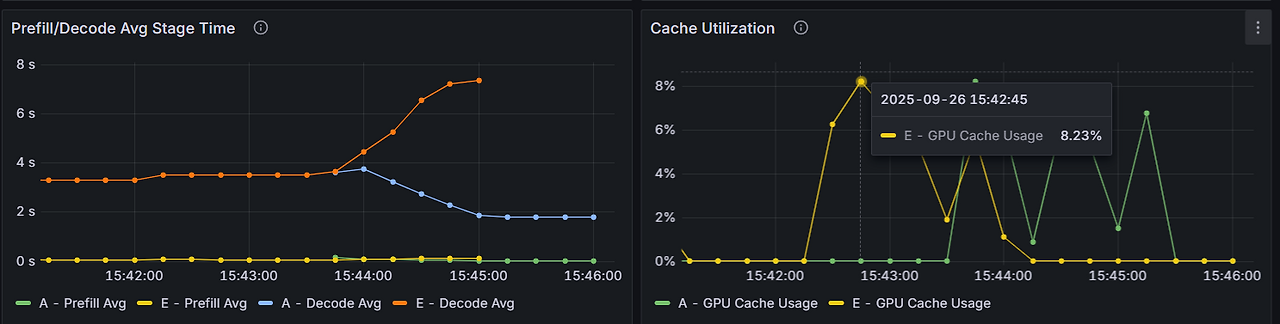
대시보드 제작 후기
대시보드를 모아 놓고 보니, finish reason에서 정상인 건과 abort/length로 중단된 건은 나눠서 확인하는 것이 좋겠다 싶다. 두 경우가 건수 차이가 클 거라, 중단된 건은 별개 패널로 확인하는 편이 나을 것 같다. 또한 분위수와 평균을 모아 그린 시계열 데이터도 좀 더 보기 좋게 하기 위해 모델마다 패널을 따로 가져가던지 아니면 50분위수, 평균을 묶고 90/95/99분위수를 묶어서 각각 별개의 패널로 가져갈지 고민해봐야겠다.
위 작업은 멀티모델일 때 테스트를 위해 진행해본 것이지만, 실제 모델 운영은 많은 처리량과 실험 효율을 위해 1개 모델만 대상으로 할 가능성이 (현재로서는) 크다. 모델을 2개 이상 올리게 되면 서빙 최적화하는 포인트도 많이 달라서, 시간이 많이 남지 않은 현재 시점에서는 선택지를 줄여 진행하는 편이 좋을 것 같다.
prometheus와 grafana에서는 특정 메트릭에 대해 운영 중 이상 현상이 발생하면 알람을 제공할 수 있다고 하던데, 회사 메일이나 문자로 연결할 수 있는지도 나중에 알아봐야겠다. codex한테 슬쩍 물어보면 한참 생각하고 친절하게 알려주겠지. codex를 비롯한 생성형AI가 없었다면 저 1500줄이나 되는 json을 수정하기에 아주 까마득했을 것 같다.. 새삼 기술의 발전에 감사하게 되었다.
종종 대시보드와 연결이 끊겨 문제가 있었는데, 이는 생성형AI도 풀지 못한 과제이긴 했다. 그냥 클라우드 연결 끊어주고 컴퓨터 껐다 켜서 작업하면 해결되곤 했다. 엣지도 크롬도 문제였던 걸 보아 뭔가 나는 잘 모르는 브라우저 캐시,, 네트워크,, 이런 문제인 거로 추정한다.
아무튼 실시간으로 언어모델을 운영하며 작업하는 과제는 처음인데 생각 이상으로 매우 재밌어서 만족도가 높다.. 처음인 것도 많고 쉽지 않은 작업이지만 잘해볼 예정,,~😄
(참고: 이 포스트는 AI의 도움을 받지 않고 사람이 직접 작성함)
참고
https://docs.vllm.ai/en/v0.7.2/getting_started/examples/prometheus_grafana.html
https://docs.vllm.ai/en/latest/design/metrics.html
https://www.dataunboxed.io/blog/monitoring-vllm-inference-servers-a-quick-and-easy-guide
Monitoring vLLM Inference Servers: A Quick and Easy Guide
Monitor vLLM on RunPod, cloud, or on-premises with Prometheus and Grafana. Includes Docker Compose setup and pre-built dashboards.
www.dataunboxed.io
'繩鋸木斷水滴石穿 > AI | 머신러닝' 카테고리의 다른 글
| [바이브코딩] Kiro와 gemini-cli를 사용해 바이브코딩으로 웹서비스 구축하기 (0) | 2025.09.14 |
|---|---|
| [생성형AI] Langgraph를 이용한 보고서 초안 생성 서비스 설계와 개발 (5) | 2025.08.10 |
| [강의] 인프런 입문자를 위한 LangChain 기초 후기 (3) | 2024.10.27 |
| [IR] Rerank: 검색 결과를 재정렬하여 RAG 성능 높이기 (1) | 2024.07.14 |
| [NLP] 텍스트 전처리: 파이썬에서 띄어쓰기, 문장 분리 라이브러리 사용하기 (3) | 2023.11.26 |