들어가며
최근 RAG 성능을 개선해야 하는 실험을 진행했습니다. 도메인 지식과 무관하게 빠르게 적용할 수 있는 기술을 알아보다 rerank를 알게 되었는데요. rerank는 말그대로 검색 결과를 다시(re-) 재정렬하는 사상을 갖고 있습니다. 질문과 답변 쌍을 갖고 있고 rerank를 위한 모델만 있으면 쉽고 빠르게 적용할 수 있어 바로 채택해 실험해보았습니다. 본 포스트에서는 rerank에 대해 간단하게 알아보겠습니다!
[사전지식] LLM, RAG, Retrieval, Rank
Rerank 도입 배경
사용자가 문장을 작성해 검색을 한다고 할 때 이 문장을 "질의(query)"라고 합니다. 검색 프로세스는 질의와 사전에 등록된 데이터를 비교하여 가장 유사한 데이터를 제공합니다. 질의와 데이터(문서, 혹은 문서를 쪼갠 문장과 청크들)를 연산이 가능한 벡터로 변환하고, 코사인 유사도나 BM25를 이용한 hybrid search 방법론을 적용해 질의와 가장 유사한 데이터가 무엇인지를 알아내는 것이죠.
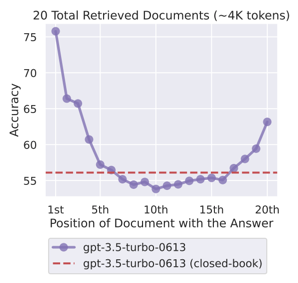
RAG(Retrieval Augmented Generation)은 너무 오래된 정보를 제공하지 않고 Hallucianation을 최소화하기 위해 최신 정보를 검색하고 이를 생성 단계에서 사용합니다. 문제는 생성 단계에서 검색된 결과를 제공하는 컨텍스트를 구성할 때 발생하는데요. "최근 논문에 따르면 RAG의 정확도는 관련 정보의 컨텍스트 내 존재 유무가 아니라 순서라는 것이 발견하였습니다. 즉, 관련 정보가 컨텍스트 내 상위권에 위치하고 있을 때 좋은 답변을 얻을 수 있다는 뜻입니다."(출처: AWS)
유사하다고 나온 정보를 많이 뽑아서 LLM에 넘기면 알아서 그 안에서 정보를 찾고 적절한 답변을 생성해주지 않는다는 것이죠. 많은 정보를 LLM에 넘겨준다고 한들 생성이 더 좋다는 보장은 없습니다. LLM에 넘겨야 하는 정보의 길이는 제한되어 있고(비용도 많이 들고..) 핵심 정보가 애매하게 위치해 있으면 성능이 낮아진다는 연구도 있다고하네요.
> 관련 논문:Lost in the Middle: How Language Models Use Long Contexts(링크)
Rerank 정의
LLM이 더 좋은 답변을 만들기 위해서는 우리가 제공해야 하는 정보의 순서가 중요하다는 것을 알았습니다. 이렇게 정보의 순서를 조정하는 단계를 rerank라고 합니다. 검색에서 한차례 선별된 정보 리스트에서 상위 k개 문서에 한정하여 순위를 재조정합니다. rerank를 위한 모델 reranker를 사용하여 최종적으로 질의에 대해 가장 의미 있는 내용을 담고 있는 문서를 보다 상위로 올리는 것을 목표로 합니다.
rerank를 사용할 때는 검색 단계에서 상위 k개 문서에 한해서만 순위를 재조정하는데요. 유사도를 이용한 검색은 전체 문서에 대해서 빠르게 결과값을 얻을 수 있지만, rerank는 질의와 문서 사이의 의미론적 유사성을 탐색하기에 그보다는 오래 걸려서, 검색을 통해서 추출된 상위 문서에 한해서만 수행해야 합니다. 상위 몇 개 문서만을 순위 재조정에 사용할지 실험하는 과정, 후보 문서를 추렸을 때 실제로 rerank가 유의미할지 정량적인 값으로 평가하는 과정도 고민해보면 좋겠습니다.
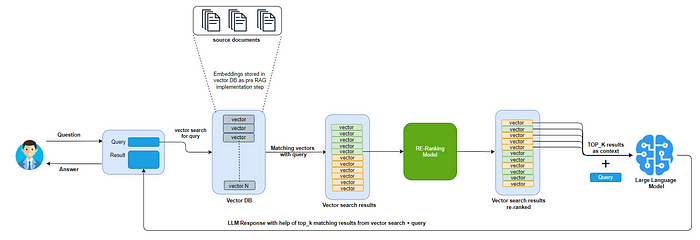
Reranker: Bi-encoder와 Cross-encoder
기존에 벡터 검색을 위해 사용하는 구조가 Bi-encoder라면, rerank를 위한 구조는 Cross-encoder입니다. Bi-encoder는 질의와 정보를 각각 임베딩한 후 유사도를 계산합니다. Cross-encoder는 질의와 정보를 입력으로 사용하여 유사도를 출력합니다. 질의와 정보를 각각 입력하고 유사도를 얻는 Bi-encoder와 다르게 질의와 정보의 내용을 한번에 고려하기 때문에 더욱 정확한 유사도를 얻을 수 있다고 합니다.
파이썬을 이용한 Rerank 예시
아래는 hugging-face에 배포된 reranker 2가지를 이용하여 간단하게 rerank 를 수행하는 코드입니다. 모델을 이용해 rerank를 하는 과정만 보여드리며, rerank 이전에 무수히 많은 문서에서 한차례 검색이 완료되어 답변 Top4를 추출했다고 가정합니다.
파이썬: v3.8.16
transformers: v4.41.2
# import library
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
import numpy as np
# set data
pairs = [
['뉴진스는 몇 년도에 데뷔했나요?', '안녕하세요.'],
['뉴진스는 몇 년도에 데뷔했나요?', '뉴진스의 데뷔 연도는 2022년입니다.'],
['뉴진스는 몇 년도에 데뷔했나요?', '2022년에는 뉴진스, 르세라핌, 엔믹스가 데뷔했습니다.'],
['뉴진스는 몇 년도에 데뷔했나요?', '뉴진스는 2022년에 데뷔하여 Hype boy 등 여러 노래를 발표했습니다.'],
]
reranker 적용1: 한국어 reranker
BAAI/bge-reranker-larger 기반 한국어 데이터에 대한 fine-tuned model 입니다.
https://huggingface.co/Dongjin-kr/ko-reranker
Dongjin-kr/ko-reranker · Hugging Face
Korean Reranker Training on Amazon SageMaker 한국어 Reranker 개발을 위한 파인튜닝 가이드를 제시합니다. ko-reranker는 BAAI/bge-reranker-larger 기반 한국어 데이터에 대한 fine-tuned model 입니다. 보다 자세한 사항은
huggingface.co
def exp_normalize(x):
b = x.max()
y = np.exp(x - b)
return y / y.sum()
model_path = "Dongjin-kr/ko-reranker"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
model.eval()
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
scores = exp_normalize(scores.numpy())
print(np.round(scores * 100, 2))[ 0. , 42.07, 1.7 , 56.23]
rerank가 제공하는 유사도를 확률로 변환하고 합이 1이 되도록하기 위해 exp_normalize를 적용하였습니다. 뉴진스가 몇 년도에 데뷔했냐는 질의에 2022년에 데뷔했다는 답변보다, 어떤 곡을 냈다는 추가 정보까지 제공하는 답변이 조금 더 유사하다고 나타났네요.
reranker 적용2: bge-reranker-v2-m3
다국어를 지원하는 bge-reranker 입니다. 경량화 되었고 빠르게 연산을 수행한다는 장점을 내세우고 있네요.
https://huggingface.co/BAAI/bge-reranker-v2-m3
BAAI/bge-reranker-v2-m3 · Hugging Face
Reranker More details please refer to our Github: FlagEmbedding. Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. You can get a relevance score by inputting query and passage
huggingface.co
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-v2-m3')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-v2-m3')
model.eval()
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
scores = exp_normalize(scores.numpy())
print(np.round(scores * 100, 2))[ 0. , 79.64, 1.55, 18.81]
앞선 한국어 reranker와는 다르게 뉴진스가 몇 년도에 데뷔했냐는 질의에 2022년에 데뷔했다는 답변이 가장 유사하다고 나타났습니다. 추가 정보를 제공하는 답변보다는 질의에 알맞은 답변만을 제공했을 때 더 유사하다고 평가하는 것 같습니다. 서비스의 목적, 사용자가 질의를 하는 의도와 기대하는 정도에 따라 어떤 reranker를 제공하는 것이 좋을지 고민해보면 좋을 것 같습니다.
위는 직접 실험해보는 경우 적용할 수 있는 코드이고, 라이브러리로 잘 구축된 리랭크를 적용하고 싶다면 LlamaIndex, Langchain 혹은 AutoRAG에서도 rerank 기능을 제공한다고 하니 활용해보시길 바랍니다.
마치며
지금까지 검색에서 순위를 재정렬하는 rerank가 왜 필요한지, 어떻게 적용할 수 있는지 간단하게 알아보았습니다. reranker는 단순하게 질문-검색 대상 데이터의 유사도를 이용하는 것보다, 질문과 검색 대상 데이터를 함께 고려하기 때문에 보다 의미론적 유사도가 높은 정보를 정확하게 찾을 수 있었습니다. 이는 나아가 generator에 더 좋은 정보를 우선 제공하여 생성 성능에도 긍정적인 영향을 줄 수 있습니다. 실제로 rerank를 적용해 실험해보니 100점 만점 기준으로 검색 정확도를 약 3.5점, 생성 정확도를 약 3점이 상승한 점을 확인할 수 있었습니다. RAG에 복잡하게 어떤 단계를 추가하기 전에 빠르게 검색, 생성 성능을 개선해보고 싶다면 rerank를 사용해보시는 것을 적극 추천합니다.
참고
https://aws.amazon.com/ko/blogs/tech/korean-reranker-rag/
한국어 Reranker를 활용한 검색 증강 생성(RAG) 성능 올리기 | Amazon Web Services
검색 증강 생성 (Retrieval-Augmented Generation, RAG)은 효율적인 데이터 검색과 대규모 언어 모델 (Large Language Model, LLM) 을 결합하여 정확하고 관련성 높은 응답을 생성하는 AI 기술로 부상했습니다. 특히
aws.amazon.com
https://huggingface.co/Dongjin-kr/ko-reranker
Dongjin-kr/ko-reranker · Hugging Face
Korean Reranker Training on Amazon SageMaker 한국어 Reranker 개발을 위한 파인튜닝 가이드를 제시합니다. ko-reranker는 BAAI/bge-reranker-larger 기반 한국어 데이터에 대한 fine-tuned model 입니다. 보다 자세한 사항은
huggingface.co
https://huggingface.co/BAAI/bge-reranker-v2-m3
BAAI/bge-reranker-v2-m3 · Hugging Face
Reranker More details please refer to our Github: FlagEmbedding. Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. You can get a relevance score by inputting query and passage
huggingface.co
Improve Retrieval Augmented Generation (RAG) with Re-ranking
In the world of GenAI, you’ll often come across the term RAG (Retrieval augmented Generation). Essentially, RAG is about giving additional…
medium.com
https://velog.io/@mmodestaa/Advanced-RAG%EC%99%80-Reranker
Advanced RAG와 Reranker
RAG의 정의, Advanced RAG와 RAG의 차이점, Reranker 설명과 llamaindex에서의 활용 예시
velog.io
'繩鋸木斷水滴石穿 > AI | 머신러닝' 카테고리의 다른 글
| [생성형AI] Langgraph를 이용한 보고서 초안 생성 서비스 설계와 개발 (5) | 2025.08.10 |
|---|---|
| [강의] 인프런 입문자를 위한 LangChain 기초 후기 (3) | 2024.10.27 |
| [NLP] 텍스트 전처리: 파이썬에서 띄어쓰기, 문장 분리 라이브러리 사용하기 (3) | 2023.11.26 |
| [NLP] 감성 분석과 ABSA(Aspect-Based Sentiment Analysis) 개념 (1) | 2023.10.09 |
| [Tips] 범주형 변수의 카테고리 개수를 줄이는 방법들 (2) | 2023.09.10 |