서비스 개요
생성형AI를 이용한 서비스 개발이 아주 장안의 화제다. 생성형AI를 적용해 여러 서비스를 만들 수 있겠지만, 업무와 연관성 있는 작업들, 특히 사무직의 꽃이라 할 수 있는 보고서 생성은 빠른 퇴근을 바라는 직장인들에게 큰 도움이 되지 않을까 싶다.
보고서 생성 서비스 만들어봐라는 얘기가 나온지는 좀 되었는데 우선순위에 밀려 있다가 최근에서야 각 잡고 이것저것 찾아보며 개발하였다. 구글 제미나이가 보고서 생성에는 다른 것 보다 낫다는 의견에 결제를 위한 품의서도 올렸다. OpenAI만 써보는 것보단 다른 것도 경험해봐야 비교도 해보고 하니 좋은 기회다.
보고서를 작성할 땐 객관적인 자료도 필요할 텐데 구글의 검색 도구를 활용할 수도 있으니 그냥 생성만 맡기는 것보다는 더 좋은 결과를 줄 수 있을 것이라 생각했다. 기본 대화하기 채팅방에서는 OpenAI 검색 도구를 적용했는데, 최신 정보 가져오는 정확도가 낮아 이 점이 아쉬웠어서, 구글을 써보면 검색 결과는 더 낫지않을까하는 기대가 있었다.
서비스 아키텍처
서비스 목표는 간단하다. 사용자가 생성하고 싶은 보고서의 주제를 입력하면, 검색 도구를 활용해 객관적인 정보를 수집하고 그를 기반으로 주제에 맞는 보고서를 생성한다(검색한 결과가 항상 객관적이며 참인지는 논외이니 나중에 생각해보자). 때문에 입력으로 주제 텍스트는 필수이다.
선택사항으로 주제를 좀 더 잘 이해하기 위해 부서명 또는 업무, 역할을 입력하도록 했고, 첨부 파일을 받는 경우에는 이를 활용하도록 했다. 동일 주제에 대해 첨부 파일의 유무에 따라 컨텐츠가 어떻게 달라지는지는 좀 더 확인해봐야 하는데, 단순하게 검색 도구와 생성에 의존하는 것보다는 사용자의 개입이 높아져 좀 더 만족스러운 결과가 나오지 않을까 기대한다.
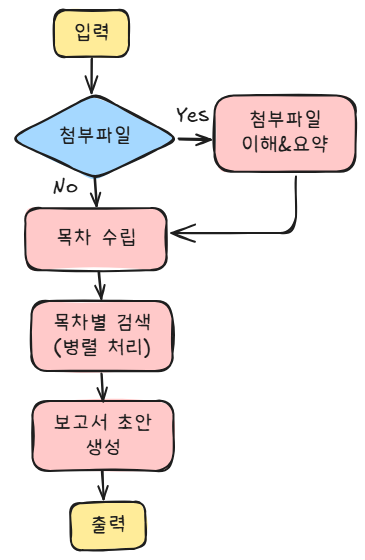
이에 따른 구조는 아래와 같다. 아키텍처는 구글 AI 스튜디오 콘솔에서 제미나이의 도움을 받아 설계했다(그림은 Excalidraw를 사용해 직접 그렸다. 안본 사이에 한국어 폰트가 예뻐졌다. 이러면 내가 작성했던 포스트가 소용이 없는데.. 아쉽다).
사용자가 첨부파일을 제공한 경우에는, 먼저 이를 이해하고 요약하도록 했다. 파일 전체를 다 활용하여 다시 쓰는 경우는 가정하지 않았고, 일단은 생성할 보고서에 활용하는 컨텐츠로 쓰임을 정의했다.
첨부 파일이 없거나, 첨부파일 요약이 끝나면 주제를 바탕으로 목차를 생성한다. 보고서이니 서론, 결론, 본론이 분명하게 있으면서 너무 소주제까지 정의하지는 않고 큰 흐름에서 5개 내외로 목차를 만든다.
이후에는 목차마다 구글 검색 도구를 이용해 관련된 컨텐츠 검색하고, 요약한다. 검색 결과도 꽤 내용이 있을테니 전부 다 컨텍스트로 넣기는 부적절하다고 생각하여 요약하도록 했다.
이후에는 보고서 초안을 생성한다. 첨부파일이 있다면 요약본도 첨부하고, 검색 결과도 컨텍스트로 제공하여 앞서 수립한 목차에 맞춰 적절하게 내용을 작성하는 과정이다.
구글 Gemini 통합과 위와 같은 구조 구현을 위해 Langgraph를 개발 프레임워크로 채택했다. 욕심 같아서는 초안 검토와 재작성, 보다 풍부한 검색까지 자동화하고 싶었는데 시간상 다음으로 미루었다. 코드는 대략적으로 아래와 같다. 구글 제미나이를 활용하기 때문에, 검색도구 사용법이나 LangGraph 구성하는 방안 등은 Google AI Studio에서 바이브코딩으로 진행하여 작업 효율을 높였다.
(더보기 클릭 시 확인 가능)
import os
from dotenv import load_dotenv
import base64
import datetime
import asyncio
from functools import partial
from typing import TypedDict, List, Optional, Literal
from langchain_core.prompts import ChatPromptTemplate
from langgraph.graph import StateGraph, START, END
from langchain_google_genai import ChatGoogleGenerativeAI
from google import genai
from google.genai import types
import vertexai
class ReportState(TypedDict):
requirement: str
role: Optional[str] # 부서명이나 역할
file_path: Optional[str] # 첨부된 파일 경로
file_summary: str # 파일 요약 내용
plan: List[str] # 목차 리스트
research_results: List[dict] # 각 목차 항목별 검색 결과
report: str
messages: List # LangGraph Agent와의 상호작용을 위함
class ReportAgent:
def __init__(self, model: str = "gemini-2.5-pro"):
self.model = model
load_dotenv()
# Gemini API 키 설정
self.api_key = os.getenv("GEMINI_API_KEY")
# Vertex AI 초기화 (set project_id)
vertexai.init(project=os.getenv("GCP_PROJECT_ID"), location="asia-northeast3")
# self.search_client = genai.Client()
self.client = genai.Client()
def encode_file(self, file_path: str, max_size: int = 5*1024*1024) -> str:
"""pdf, txt 파일을 base64로 인코딩함
Args:
file_path (str): pdf, txt파일 경로
Returns:
encoded_file (str): base64로 인코딩된 파일
Raises:
FileNotFoundError: 파일이 존재하지 않을 경우 발생.
ValueError: 지원되지 않는 파일 형식일 경우 발생.
OSError: 파일 읽기 중 문제가 발생할 경우 발생.
"""
# 파일이 존재하는지 확인
if not os.path.exists(file_path):
raise FileNotFoundError(f"File not found: {file_path}")
# 파일의 확장자 확인
if not (file_path.endswith('.pdf') or file_path.endswith('.txt')):
raise ValueError("Unsupported file type. Only PDF and TXT files are supported.")
# base64로 인코딩 (streaming approach)
encoded_file = ""
with open(file_path, "rb") as file:
for chunk in iter(lambda: file.read(max_size), b""):
encoded_file += base64.b64encode(chunk).decode('utf-8')
return encoded_file
def generate_file_summary(
self,
file_path: str,
model: str = "gemini-2.5-pro",
temperature: float = 0.5,
max_output_tokens: int = 4096
) -> str:
"""file_path 받아 인코딩 후, gemini를 이용하여 요약을 생성합니다.
Args:
file_path (str): 인코딩된 텍스트 객체
Returns:
response.text (str): gemini가 요약한 파일의 주요 내용
"""
# Read config file
report_config = "prompt를 저장했던 yaml 읽으세요. 커스텀 함수여서 가립니다.."
config = types.GenerateContentConfig(
system_instruction=report_config['FILE_SUMMARY_PROMPT'],
temperature=temperature,
max_output_tokens=max_output_tokens,
)
# Encode the file
encoded_file = self.encode_file(file_path)
if file_path.endswith('.pdf'):
mime_type = 'application/pdf'
elif file_path.endswith('.txt'):
mime_type = 'text/plain'
else:
raise ValueError("Unsupported file type. Only PDF and TXT files are supported.")
# Generate content using the model
response = self.client.models.generate_content(
model=model,
contents=[
types.Part.from_bytes(
data=encoded_file,
mime_type=mime_type,
)
],
config=config,
)
return response.text
def get_web_search_summary(
self,
requirement: str,
temperature: float = 0.5,
max_output_tokens: int = 4096
) -> str:
"""웹 검색을 수행하고 요약된 결과를 반환합니다."""
# Define the grounding tool
grounding_tool = types.Tool(
google_search=types.GoogleSearch()
)
# 2. 웹 검색 및 요약
print("웹 검색을 수행하고 있습니다...")
# Configure web search with grounding tool
web_search_prompt = """다음 사용자가 입력한 주제에 대해 웹에서 최신 정보를 검색하여 가장 중요한 내용을 요약해 주세요."""
web_search_config = types.GenerateContentConfig(
system_instruction=web_search_prompt,
temperature=temperature,
tools=[grounding_tool],
max_output_tokens=max_output_tokens
)
# Make the web search request
web_search_response = self.client.models.generate_content(
model="gemini-2.5-flash",
contents=requirement,
config=web_search_config,
)
# 출처 URL을 포함한 검색 결과를 출력
print("\n--- 웹 검색 요약 결과 ---")
if not web_search_response.text:
print("No response text received from the web search.")
else:
print(web_search_response.text[:100])
citations = self.get_citations(web_search_response)
print("------------------------웹 검색 종료------------------------")
return web_search_response.text + citations
def get_citations(self, response) -> str:
"""response에서 검색 결과의 출처 URL을 추출하여 반환합니다.
Args:
response: web_search tool output
Returns:
(str): citations
"""
try:
text = response.text
chunks = response.candidates[0].grounding_metadata.grounding_chunks
if not chunks:
print("No grounding chunks found in the response.")
return text
# Add source url information to the response text
else:
source = "\n\n[검색 출처]"
for i, chunk in enumerate(chunks):
chunk_url = chunk.web.uri
chunk_title = chunk.web.title
if 'vertexai' in chunk_url:
# Extract the URL from the vertexai link
# e.g.) [1] (aaa.com) [https://vertexai.com/~~~~~~]
source += f"\n[{i+1}] [{chunk_title}]({chunk_url})"
return source
except:
print("Error occurred while adding citations to the response.")
return ""
def check_file_exists(self, state: ReportState) -> Literal["file_summarizer", "planner"]:
"""파일 경로가 존재하는지 확인 후 다음 단계를 정의(분기 노드)"""
print("\n--- 📎 파일 존재 여부 확인 단계 진입 ---")
file_path = state.get("file_path")
if file_path and os.path.exists(file_path):
return "file_summarizer"
print("파일이 없어 목차 생성 단계로 넘어갑니다.")
return "planner"
# 파일 요약 노드: 파일을 읽고 요약을 생성하는 단계
def generate_file_summary_step(self, state: ReportState) -> dict:
"""파일이 있는 경우에 파일 요약을 수행하는 노드"""
print("\n--- 📎 파일 요약 단계 진입 ---")
file_path = state.get("file_path")
if file_path:
summary = self.generate_file_summary(file_path)
return {"file_summary": summary}
else:
print("...첨부된 파일이 없어 이 단계를 건너뜁니다.")
return {"file_summary": ""} # 파일이 없을 경우 빈 문자열 반환
def plan_step(self, state: ReportState) -> dict:
"""보고서 목차를 생성하는 단계"""
print("\n--- 📝 1단계: 보고서 계획 수립 ---")
# 파일 요약이 있으면 프롬프트에 추가
file_context = ""
if state.get("file_summary"):
file_context = f"\n다음은 사용자가 첨부한 파일의 핵심 요약 내용입니다. 보고서 계획 시 반드시 이 내용을 참고하세요:\n--- [파일 요약] ---\n{state['file_summary']}\n--------------------"
PLANNER_PROMPT = f"""~~보고서 기획일을 시키는 프롬프트~~{file_context}"""
prompt_template = ChatPromptTemplate.from_messages([
("system", PLANNER_PROMPT),
("human", "주제: '{requirement}'\n부서: '{role}'")
])
# LangChain에서 사용할 Gemini 모델
plan_llm = ChatGoogleGenerativeAI(
model=self.model,
google_api_key=self.api_key,
temperature=0.5,
)
plan_chain = prompt_template | plan_llm.with_config({"run_name": "Planner"})
response = plan_chain.invoke({"requirement": state['requirement'], "role": state['role']})
# LLM의 출력(문자열)을 리스트로 변환
plan_list = [item.strip() for item in response.content.strip().split("\n") if item.strip()]
print("📊 생성된 목차:")
for item in plan_list:
print(f"- {item}")
return {"plan": plan_list}
async def aresearch_step(self, state: ReportState) -> dict:
"""Research 노드: 목차별 웹 검색을 병렬로 수행"""
print("\n--- 🔬 2단계: 목차 기반 정보 수집 (concurrent) ---")
try:
requirement = state["requirement"]
plan = state["plan"] # e.g. ['시장 규모', '경쟁사', …]
loop = asyncio.get_event_loop()
semaphore = asyncio.Semaphore(5) # 동시에 5개까지 실행 (필요시 조정)
async def _search(item: str) -> dict:
async with semaphore: # 🔒 Rate-limit / 비용 제어
query = f"{requirement}에 대한 상세 내용, 특히 '{item}'에 초점을 맞춤"
# 동기 함수 → thread-pool에서 실행
summary = await loop.run_in_executor(
None, # 기본 ThreadPoolExecutor
partial(self.get_web_search_summary, query)
)
return {"requirement": item, "summary": summary}
tasks = [asyncio.create_task(_search(item)) for item in plan]
research_results = await asyncio.gather(*tasks)
return {"research_results": research_results}
except Exception as e:
return {"research_results": []} # 에러 발생 시 빈 리스트 반환
def write_step(self, state: ReportState) -> dict:
"""Write 노드: 수집된 정보로 최종 보고서 작성"""
print("\n--- ✍️ 3단계: 최종 보고서 작성 ---")
research_data = state.get("research_results", "")
file_summary = state.get("file_summary", "")
# 리서치 결과를 보고서 작성에 적합한 형태로 포맷팅
formatted_research = "\n\n".join([
f"## {res['requirement']}\n\n{res['summary']}" for res in research_data
])
# 리포트 프롬프트에 파일 요약 섹션 추가
file_context_for_writer = ""
if file_summary:
file_context_for_writer = f"### 1. 사용자가 첨부한 파일 핵심 내용\n\n{file_summary}\n\n"
WRITER_PROMPT = f"""~~초안 작성 프롬프트~~{file_context_for_writer}
"""
prompt_template = ChatPromptTemplate.from_messages([
("system", WRITER_PROMPT),
("human", "사용자의 부서(또는 역할): {role}\n주제: {requirement}\n\n--- 리서치 자료 ---\n{research}\n\n--- 지시사항 ---\n위 리서치 자료를 바탕으로 최종 보고서를 작성하세요.")
])
writer_llm = ChatGoogleGenerativeAI(
model=self.model,
google_api_key=self.api_key,
temperature=0.7,
max_output_tokens=1024*8,
)
writer_chain = prompt_template | writer_llm.with_config({"run_name": "Writer"})
final_report = writer_chain.invoke({
"role": state["role"],
"requirement": state["requirement"],
"research": formatted_research
}).content
return {"report": final_report}
async def amain(
self,
user_id: str,
requirement: str,
role: str = "",
file_path: str = "",
) -> str:
graph_builder = StateGraph(ReportState)
graph_builder.add_node("check_file_exists", self.check_file_exists)
graph_builder.add_node("file_summarizer", self.generate_file_summary_step)
graph_builder.add_node("planner", self.plan_step)
graph_builder.add_node("researcher", self.aresearch_step)
graph_builder.add_node("writer", self.write_step)
# ─── Entry & Branch ─────────────
graph_builder.add_conditional_edges(
START,
self.check_file_exists,
{
"file_summarizer": "file_summarizer",
"planner": "planner"
},
)
# ─── Main flow ──────────────────
graph_builder.add_edge("file_summarizer", "planner")
graph_builder.add_edge("planner", "researcher")
graph_builder.add_edge("researcher", "writer")
graph_builder.add_edge("writer", END)
# Graph 컴파일 및 실행
graph = graph_builder.compile()
final_state = await graph.ainvoke({"requirement": requirement, "role": role, "file_path": file_path})
return final_state['report'] # str
개발 시 고려점 및 향후 개선점
고려사항/에러사항
1) 첨부 파일의 종류와 크기는?
- 모든 파일 종류를 받을 수 없고, 크기도 제한 없이 풀어 두어서는 안된다. 제미나이가 읽을 수 있는 파일의 크기제한도 있는 것으로 안다. 파일 타입마다 백엔드에서 읽어야하고 인코딩도 해야하니 가능한 수준에서 설정한다.
2) 첨부 파일을 생성형 AI에 어떻게 제공할 것인지?
- 파일에 있는 텍스트를 크롤링하여 제공할 것인지(문서 이해하고 크롤링해주는 라이브러리 필요함), 요즘에는 바로 AI한테도 넘겨도 잘 이해하니 API를 활용할 것인지(비용 부담 있음) 효율성과 운영 비용 측면에서 검토하고 결정한다.
3) 목차별 검색할 때 시간이 너무 오래 걸리는 점
- 최초 개발 시에 목차들마다 순차적으로 검색 및 요약 요청을 날렸는데 시간을 너무 오래 잡아먹었다. 어차피 동일한 요구인데 병렬 처리해도 되겠지 싶어 비동기 병렬 처리했다. 다만 이 방법은 운이 좋지 않으면 too much request 에러를 발생시키니 주의해야 한다.
4) 보고서 다운로드는 무슨 형식으로?
- 일반적으로 사용할거라 생각되는 Word를 채택하긴 했는데, 프론트에서 워드 형식을 제공하는 과정에서 조금 처리가 필요하다. 프론트개발자와 원만하게 합의하길 바란다.
5) 모델 선택은? 파라미터는?
- Gemini-2.5-Pro가 좋다고 하지만 모든 작업마다 얘를 호출했다가는 비용을 감당하기 어려울 수도 있다. 작업 난이도에 따라 적절하게 선택해야한다. 또한 생성 작업들마다의 역할을 잘 이해하여 temperature나 max_token과 같은 값도 조절해야한다. 즉, 서비스와 구조에 대한 이해가 있어야 최적화 포인트를 찾아낼 수 있다는 점..!
향후 개선점
1) 제공방식은 멀티턴? 싱글턴?
- 우선은 멀티턴, 채팅방식이 아닌 싱글턴으로 개발했다. 다만 이경우에 다시 써달라, 일부만 수정하고 싶다는 등의 요청 반영이 어렵다. 물론 멀티턴으로 개발이야 할 수는 있겠지만, 모든 생성형AI 서비스의 결과를 멀티턴 방식으로 제공하는 것이 효율적인 것은 아니니 고민해보자.
2) 전문 에이전트들의 협업?
- 지금은 일반적인 보고서만 생각하고 설계했는데, 좀더 전문적인 에이전트들이 필요할 수 있겠다. 예를 들어 투자에 대한 조언이라면, 경제 전문가, 재무 컨설턴트, 투자 전문가 등.. 좀 더 구체적으로 정의된 에이전트를 미리 만들어 두고 사용자 요구사항에 맞게 적절히 도구(에이전트)를 호출해 작업을 진행하도록 할 수도 있겠다.
참고
1-1. 랭그래프 LangGraph 소개
## 랭그래프 (LangGraph) 소개 LangGraph는 자연어 처리와 AI 응용 프로그램 개발을 위한 강력한 프레임워크로, 복잡한 언어 모델과의 상호작용을 효율적이고 구조…
wikidocs.net
https://cloud.google.com/vertex-ai/generative-ai/docs/multimodal/document-understanding?hl=ko
문서 이해 | Generative AI on Vertex AI | Google Cloud
의견 보내기 문서 이해 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. 문서(PDF 및 TXT 파일)를 Gemini 요청에 추가하여 포함된 문서의 콘텐츠 이해와 관련된 태
cloud.google.com
'繩鋸木斷水滴石穿 > AI | 머신러닝' 카테고리의 다른 글
| [바이브코딩] codex를 이용한 vllm 대시보드 구현 (1) | 2025.09.28 |
|---|---|
| [바이브코딩] Kiro와 gemini-cli를 사용해 바이브코딩으로 웹서비스 구축하기 (0) | 2025.09.14 |
| [강의] 인프런 입문자를 위한 LangChain 기초 후기 (3) | 2024.10.27 |
| [IR] Rerank: 검색 결과를 재정렬하여 RAG 성능 높이기 (1) | 2024.07.14 |
| [NLP] 텍스트 전처리: 파이썬에서 띄어쓰기, 문장 분리 라이브러리 사용하기 (3) | 2023.11.26 |