
JSON 파일이란? JSON은 JavaScript Object Notation의 약자로 JavaScript 언어의 자료형을 텍스트로 표현한 포맷입니다. 키-값 쌍으로 이루어져 있으며 사람이 쉽게 읽을 수 있도록 구성되어 있습니다. 서로 다른 시스템간에 데이터를 교환하기에 좋고, 언어가 다르더라도 데이터를 교환하는데 용이하다는 장점이 있습니다. JSON은 데이터를 키(key)와 값(value)로 표현하고, 이를 중괄호 {}로 감싸서 표현합니다. 예를 들면 {"점수" : 80} 이런 식이죠. 키는 큰따옴표로 묶은 문자열이고, 여러 개의 키-값 쌍을 저장하고 싶다면 쉼표(, comma)로 구분합니다. 만약 값으로 둘 이상의 값들을 사용하고 싶다면 대괄호 []로 묶어주면 됩니다. ex) {"singer": "T..
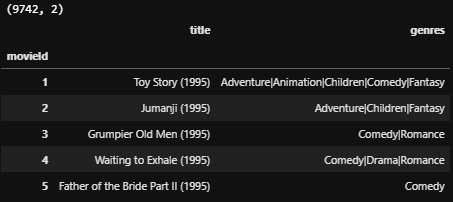
데이터프레임 형태를 갖는 어떤 데이터가 있다고 합시다. 이 데이터의 한 칼럼은 하나의 값이 아니라 여러 개의 값을 갖고 있습니다. 각각의 값들이 하나의 칼럼이 되어 새로운 값을 갖도록 하려면 어떻게 해야 할까요? 한 강의를 듣다가 문득 궁금증이 생겼는데, 강사님께서 직접 찾아보라고 하셔서 ㅎ.. 알아보았습니다. 유용하게 쓰일 법한 테크닉인데, 구현하는 방법은 굉장히 단순해서 놀랐어요. 데이터 준비 import os import pandas as pd import numpy as np from tqdm import tqdm path = '../data/movielens' movies_df = pd.read_csv(os.path.join(path, 'movies.csv'), index_col='movieId..
파이썬에서 tabular 형식으로 갖춰진 데이터를 다룰 때 보통 판다스를 가장 먼저 사용하죠. 판다스는 칼럼이 가질 수 있는 자료형으로 숫자, 문자, 날짜, boolen(True or False) 등을 지원합니다. 판다스로 데이터프레임을 다뤄보다가 문득 object 형식과 category 형식이 정확히 어떤 차이인지 궁금해졌어요. 그래서 이 포스팅에서는 두 형식의 개념과 차이에 대해 알아보고자 합니다. 판다스에서 자료형으로 사용되는 object와 category의 개념은 다음과 같이 이해할 수 있습니다. object 판다스에서는 문자열을 object라는 자료형으로 나타냅니다. 파이썬에서는 문자열을 string이라고 하지만, 판다스는 object라고 합니다. pd.DataFrame을 사용하여 데이터프레임을..
11. Create a 3x3 identity matrix (★☆☆) mat1 = np.identity(3) mat2 = np.eye(3) print(mat1) print(mat2) [[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]] [[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]] 12. Create a 3x3x3 array with random values (★☆☆) mat = np.random.random((3, 3, 3)) print(mat) [[[0.5282567 0.309261 0.76337568] [0.43948225 0.90048663 0.58643259] [0.20646 0.56080675 0.1688716 ]] [[0.50961462 0.17716085 0.857..

『밑바닥부터 시작하는 딥러닝 2』 공부를 시작했다! 두근두근😝 www.yes24.com/Product/Goods/72173703?OzSrank=3 밑바닥부터 시작하는 딥러닝 2 직접 구현하면서 배우는 본격 딥러닝 입문서 이번에는 순환 신경망과 자연어 처리다! 이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데 www.yes24.com 첫 장은 신경망 복습으로, 이전 1권에서 다룬 내용이 요약되어있다. 1권을 공부한지 얼마 안되었지만, (난 멍청하기 때문에) 다시 복습하는 의미로 첫 장부터 보고 있다. 넘파이에 행렬 계산을 돕는 메소드가 많이 준비되어 있다는 설명에 넘파이 경험을 쌓고 싶으면 '100 numpy exercises' 문제를 풀으라는 노트가..
1. 사용자 정의 함수를 만들어 apply로 적용하기 > df["새로운 칼럼명"] = df["기존 칼럼명"].apply(사용자 정의 함수) 2. loc 메소드 활용하기 > df.loc[조건, "새로운 칼럼명"] = "변경할 값" 3. replace 메소드 활용하기 > df["새로운 칼럼명"] = df["기존 칼럼명"].replace("기존 값1", "변경할 값1").replace("기존 값2", "변경할 값2") ...

Pandas 기초 마지막 포스팅입니다. 여기서는 데이터를 요약하는 몇가지 함수들을 알아보겠습니다. describe() : 수치형 칼럼 요약 grades.describe().round(2) describe()는 수치형 값을 갖는 칼럼에 한해 count(빈도수), mean(평균), std(표준편차), min(최솟값), 25%(제1사분위수), 50%(제2사분위수), 75%(제3사분위수), max(최댓값)를 제공합니다. round(N)는 소수점 자리수에서 반올림을 해주는 함수인데, N+1번째 자릿수에서 반올림하여 소숫점 아래 숫자를 N개만 남깁니다. quantile() : 분위수 구하기 grades.quantile([0.1, 0.4, 0.7, 0.9]) 사용자가 직접 구하고 싶은 분위수를 지정하여 값을 얻을 수..
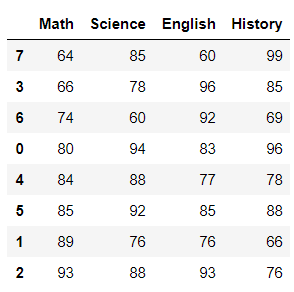
지난 포스팅()에서는 Pandas 라이브러리를 활용하여 데이터프레임 만들기, 조회하기를 알아보았습니다. 이번 포스팅에서는 만들어진 데이터프레임을 활용하여 칼럼명 변경, 정렬, 결합 그리고 칼럼 순서 변경에 대해 알아보겠습니다. rename : 칼럼명 변경 특정 칼럼의 이름을 변경하기 위해 rename()을 사용합니다. 여기서는 Math 칼럼의 이름을 MATH로 변경하였습니다. print(grades.columns) grades.rename(columns = {'Math':'MATH'}, inplace = True) print(grades.columns) Index(['Math', 'Science', 'English', 'History'], dtype='object') Index(['MATH', 'Scie..
pandas_tutorial-1 Pandas tutorial 1 - 데이터 만들기부터 조회까지¶ tidy data란¶데이터 분석을 위해선 정돈된 형태의 데이터를 구축해 놓는 것이 필수적이죠. 타이디(tidy, 깔끔한) 데이터는 작업하기 매우 용이한, 정형화된 형태의 데이터로, 다음을 만족해야 합니다. 각 관측값마다 해당되는 행이 있어야하고, 각 변수마다 해당되는 열이 있어야하고, 값마다 해당하는 하나의 셀이 있어야 합니다. 일반적으로 엑셀에 데이터를 입력하는 방식과 동일하다고 생각하시면 됩니다. 예를 들어, 어떤 학급에서 학생들이 시험을 치루었고, 그 성적을 입력한다고 합시다. 각 열은 해당 학급에 속하는 학생의 번호, 이름, 국어점수, 수학점수, 영어점수를 의미하고, 각 행은 한명의 학생에 대한 관측값..
Numpy는 과학 계산을 위해 반드시 필요한 패키지입니다. 다차원 배열을 위한 기능과 선형 대수 연산, 수학 함수, 유사 난수 생성기를 포함합니다. 핵심 기능은 다차원 배열인 ndarray 클래스로, 이 배열의 모든 원소는 동일한 데이터 타입이어야 합니다. 1. 배열 만들기 numpy 배열은 리스트로 구현합니다. import numpy as np a = np.array([1, 2, 3]) b = np.array([[1.5, 2, 3], [4, 5, 6]]) print(a) print(b) [1 2 3] [[1.5 2. 3. ] [4. 5. 6. ]] np.zeros([행의 수, 열의 수]) np.zeros([3, 4]) # 영행렬 생성 array([[0., 0., 0., 0.], [0., 0., 0., ..